개요
논문 링크: https://arxiv.org/abs/2006.07733 (Bootstrap Your Own Latent)
Self-supervised learning 기법 중 하나이다. 아이디어는 간단하다. 두 개의 network를 사용하는데 논문에서 각각 online network, target network라고 부른다. Target network는 online network의 일부를 (중요) exponential moving average로 얻는다. 이미지를 각각 augmentation을 해서 online network, target network에 통과시키고, target network로 encoding된 feature을 online network가 예측하도록 학습을 한다.
방법
Motivation
- 이 분야에서 Contrastive learning이 인기있는 방법 중 하나인데, 이 방법에서는 같은 이미지를 다른 방식으로 augmentation하면 서로 비슷하고 (positive examples), 데이터셋에 있는 다른 이미지들과는 (negative examples) 다르다는 것을 예측하도록 neural network를 학습시킨다. 하지만 이런 방식들이 잘 작동하려면 보통 많은 negative examples들이 필요하다. 이런 negative example들 없이 과연 neural network를 학습 시킬 수 있을 까?
- 당연히 한 neural network에 같은 이미지를 다른 방식으로 augmentation을 해서 통과시키고, 결과가 서로 같게 나오도록 학습시키면 모든 이미지를가 feature을 갖게 되도록 collapse가 일어날 것이다.
- 하지만 각각 online, target network라고 불리는 두 개의 neural network를 사용해보자. 여기서 target network는 random initialization을 해주고 (online network와 다르게) 고정시켜버린다. 같은 이미지를 각각 augmentation을 해서 online, target network에 통과시키고, online network의 output이 target network의 output을 예측하게 학습시키면 의외로 괜찮은 feature을 학습할 수 있다: 이렇게 학습된 image feature에 linear classifier을 학습시키면 18.8% top-1 accuracy (ImageNet)를 얻을 수 있다. 반면 random initialized된 neural net을 통과시킨 image feature에 linear classifier을 학습시키면 1.4% top-1 accuracy가 나온다.
- 그러면 online network가 성능이 좋아진 후, target network를 업데이트 시켜주고, 다시 online network를 학습시키고,..., 이 과정을 계속 반복을 하면 더 좋은 결과를 얻을 수 있을 것이라는 기대가 이 논문의 motivation.
Method Details
그림을 참고하면 이해하기 쉽다.
- Online network 구성 요소:
- \( f_\theta \): encoder; ResNet같은 convolutional neural net이라고 생각하면 된다
- \( g_\theta \): projector; encoder에서 나온 feature을 프로세싱 해주는 MLP라고 생각하면 된다
- \( q_\theta \): predictor; target network의 feature을 예측할 때 도움을 주는 network이며 MLP라고 생각하면 된다.
- Target network 구성 요소: online network와 기본적으로 같지만 predictor이 없다. 또 다른 차이점은 neural net의 parameter인데, 학습 과정에서 online network의 parameter의 exponential moving average로 얻는다: \( \xi = \tau \xi + (1-\tau) \theta\). \( \tau는 \) 0에서 1 사이 값을 갖는다.

- 기본적으로 이미지로부터 \( q_\theta (z_\theta)\)와 \( z'_\xi\)를 얻은 후 unit normalize해서 (\( \bar{~} \)로 표기) L2 loss를 사용한다:

- online network와 target network에 들어가는 이미지를 서로 교환해서 동일하게 loss \( \tilde{\mathcal{L}}_{\theta,\xi} \) 를 계산한다. BYOL loss는 다음과 같이 symmetric하게 계산한다: \( \mathcal{L}^{BYOL}_{\theta,\xi} = \mathcal{L}_{\theta,\xi} + \tilde{\mathcal{L}}_{\theta,\xi}\)
- 학습을 완료하면 encoder \( f_\theta\)만 사용한다.
- 정리하면 다음과 같은 알고리즘을 얻게 된다

학습 디테일
- Augmentation: random crop, flip, color distortion
- LARS optimizer, cosine decay learning rate schedule 의 일종 사용
왜 collapse안하는가?
접은글에 설명했뒀는데, 논문에서 이 부분을 읽어보면 좀 이상하고, SimSiam이나 BYOL같은 방식이 왜 collapse하지 않는지에 대해서 분석하는 논문들도 따로 있다. BYOL 논문에 적혀있는 설명은 무시하고 이런 논문들을 참고하는 것을 추천한다.
\( \theta = \xi\)이고 predictor이 identity가 되면서 collapse할 가능성은 있다. 하지만 실제로는 이렇게 되지 않았다고 한다.
논문에 설명이 좀 이상해서 이것저것 자료를 찾아봤는데, 이 부분을 제대로 설명하는 자료는 찾지 못했다. 왜 이상하다고 생각하는지 밑에 설명해보겠다 (저자들의 주장이 맞다고 생각하면 이유를 댓글을 부탁드립니다...) v1에서는 이 내용이 없고, nips review를 보면 refereee들이 대략적인 이론적인 설명이 있으면 좋겠다고 요구해서 추가되었다. 정리하자면 저자들은 다음과 같이 주장한다:
- 우선 분석을 간단하게 하기 위해서 loss를 계산할 때 unit normalization & symmetrization을 무시하자. 이 부분이 없으면 성능 저하는 있지만 collapse는 하지 않는다.
- Predictor이 핵심적인 역할을 한다
- Optimal한 predictor \( q^*\)이 있다고 하자:
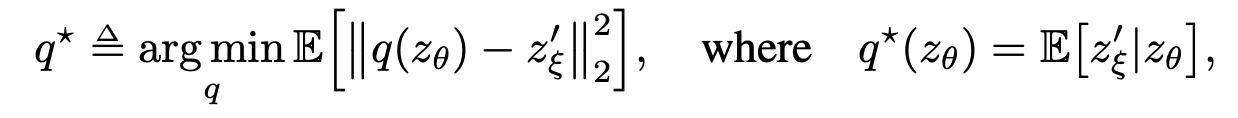
- 다음과 같은 식을 얻을 수 있다고 한다 (유도 과정은 논문 appendix 참고):
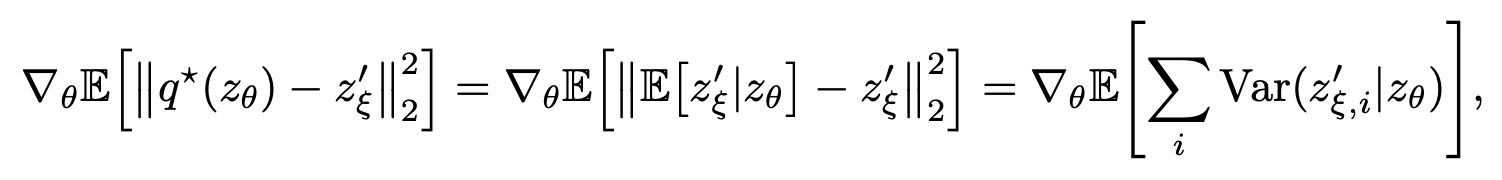
- 여기서 \( z'_{\xi,i}\)는 i번째 component를 뜻한다.
- 논문에 random X, Y, Z가 있을 때 \( Var(X|Y,Z) \le Var(X|Y)\)가 일반적으로 성립한다고 한다. 조금 이상해서 찾아봤는데 우선 이 식은 틀렸다 (Notation을 특이하게 사용하고 있는 것이 아니라면...): https://www.quora.com/Is-conditional-variance-of-a-random-variable-always-less-or-equal-to-its-unconditional-variance. 이 식에 expectation value를 씌워야 맞다: https://statweb.rutgers.edu/hcrane/Teaching/582/lectures/chapter18-condexp.pdf 패이지 76에서 g(x)를 상수 E(Y)로 바꾸면 됨.
- X를 target prediction, Y를 online prediction,Z는 stochasticity때문에 들어오는 변수라고 해석하자. 그러면 constant c에 대해서 \( Var(z'_\xi | z_\theta) \le Var(z'_\xi|c)\) -> loss가 더 커진다고 해석 가능하다고 주장한다. 이유는 constant로 두면 정보를 무시하는 거니까 정보가 더 있는 것보다 variance가 클 것이라는 기다. 또한 c를 collapsed online network의 output으로 해석하면 collapse된 network의 loss가 높으니까 unstable할 것이라고 주장 (논문에서 loss라고 표현은 안하지만 결국 그 뜻이다)
- 하지만 식 그대로 해석하면 이상하다. 애초에 conditional variance에서는 \( z_\theta\)는 고정되어 있다. \( z_\theta = c\)라고 한다고 Variance가 높아진다는 뜻은 아닐 것이다.
- 만약 이전에 언급한 식 \( Var(X|Y,Z) \le Var(X|Y)\) 처럼 notation 문제이고 conditional variance가 아니라 conditional variance의 expectation value를 말하고 있는 것이라고 가정하자. 다시 말해서 어떠한 \( p(z_\theta) \)에 대한 conditional variance의 expectation value보다 collapsed distribution (i.e. delta distribution) \( p(z_\theta) = \delta(z_\theta - c)\)가 더 큰 \( E(Var(z'_\xi | z_\theta)) \)를 준다는 뜻이라고 해석해보자. 이것도 이상하다; 그럴 이유가 없다 (굳이 반례를 들지 않겠다...).
- \( Var(X|Y,Z) \le Var(X|Y)\)에서 Stochasticity를 언급했기 때문에 stochasticity를 무시하면 더 conditional variance의 평균 값 (i.e. loss) 가 커진다는 해석이라고 이해해보면 그나마 말이 되는 것 같지만 가만히 생각해보면 이것도 이상하다. collapse되는 것과 variable을 '무시'하는 것과 전혀 다른 현상이기 때문이다: Collapse하는 것은 \( z_\theta\)가 delta distribution을 갖는 것이고 (모든 이미지에 대해서 같은 feature을 뱉어내는 현상), 변수를 '무시' (저자들 언어로는 discarding information) 하는 것은 그냥 random variable을 관측하지 않은 상태에서 variance를 계산한다는 뜻이기 때문이다. 따라서 stochasticity에 대한 정보를 discard 하는 것은(\( Var(X|Y,Z) \le Var(X|Y)\) 식에 내포된 의미) collapse하는 것 ( \( Var(z'_\xi | z_\theta) \le Var(z'_\xi|c)\) )과 별로 관계가 없다.

결국 NIPS 논문 리뷰에 대한 저자들의 답변도 찾아봤다: training dynamics의 variability 정보를 집어넣어주면 conditional variance가 줄어들어야한다고 주장한다. 하지만 variability 정보를 빼는 것은 constant로 두는 것과 다르지 않은가...?

결과
다른 방식보다 성능이 좋다
SimCLR, MoCo같은 방식보다 다양한 task에 대해서 linear classification (ImageNet), transfer learning, 등등 더 성능이 좋다고 한다. 별로 설명할 것이 없기 때문에 관심 있으면 논문 참고.
Ablation study
SimCLR보다 Batch size를 더 작게해도 괜찮고 augmentation에 dependency도 적다

Exponential moving average를 너무 빨리 하거나 (현제 Network 사용) 천천히 하면 문제가 있다 (당연하게도)

BYOL이랑 SimCLR을 비교하기 위해서 다양한 실험을 하는데, 개인적으로 흥미로운 것은 BYOL에서 predictor을 제거하면 collapse가 일어나는 것이다: 밑에 table에서 밑에서 2번 째 줄에 해당 (Top-1: 0.3). 또한 target network를 제거해도 collapse한다: 밑에서 3번째 줄에 해당.

추가 노트
개인적으로 관심있는 포인트는 collapse 안하는 요소들인데, 실험적으로 predictor & exponential moving average가 이것을 가능하게 한다. Predictor이 있기 때문에 online network와 target network의 asymmetry가 생기면서 neural network의 collapse를 일부 방지하는 것 같다. 또한 exponential moving average를 사용하기 때문에 두 network가 정확히 같게 되지 않고 이 요소가 또한 collapse를 방지하는데 도움이 되는 것 같다l. Referee에 답한다고 collapse가 일어나지 않는 이유는 나름 설명하려고 했지만 별로 설득력이 없다고 생각한다 (제가 이해력이 부족한 것이 아니면).
'논문 리뷰 > self-supervised learning' 카테고리의 다른 글
| [논문 리뷰] SwAV (0) | 2023.03.11 |
|---|---|
| [논문 리뷰] SeLa (0) | 2023.03.04 |
| [논문 리뷰] DeepCluster (Deep Clustering for Unsupervised Learning of Visual Features) (1) | 2023.02.26 |
| [논문 리뷰] MoCo-v2 (0) | 2023.02.24 |
| [논문 리뷰] MoCo-v1 (Momentum Contrast for Unsupervised Visual Representation Learning) (0) | 2023.02.24 |