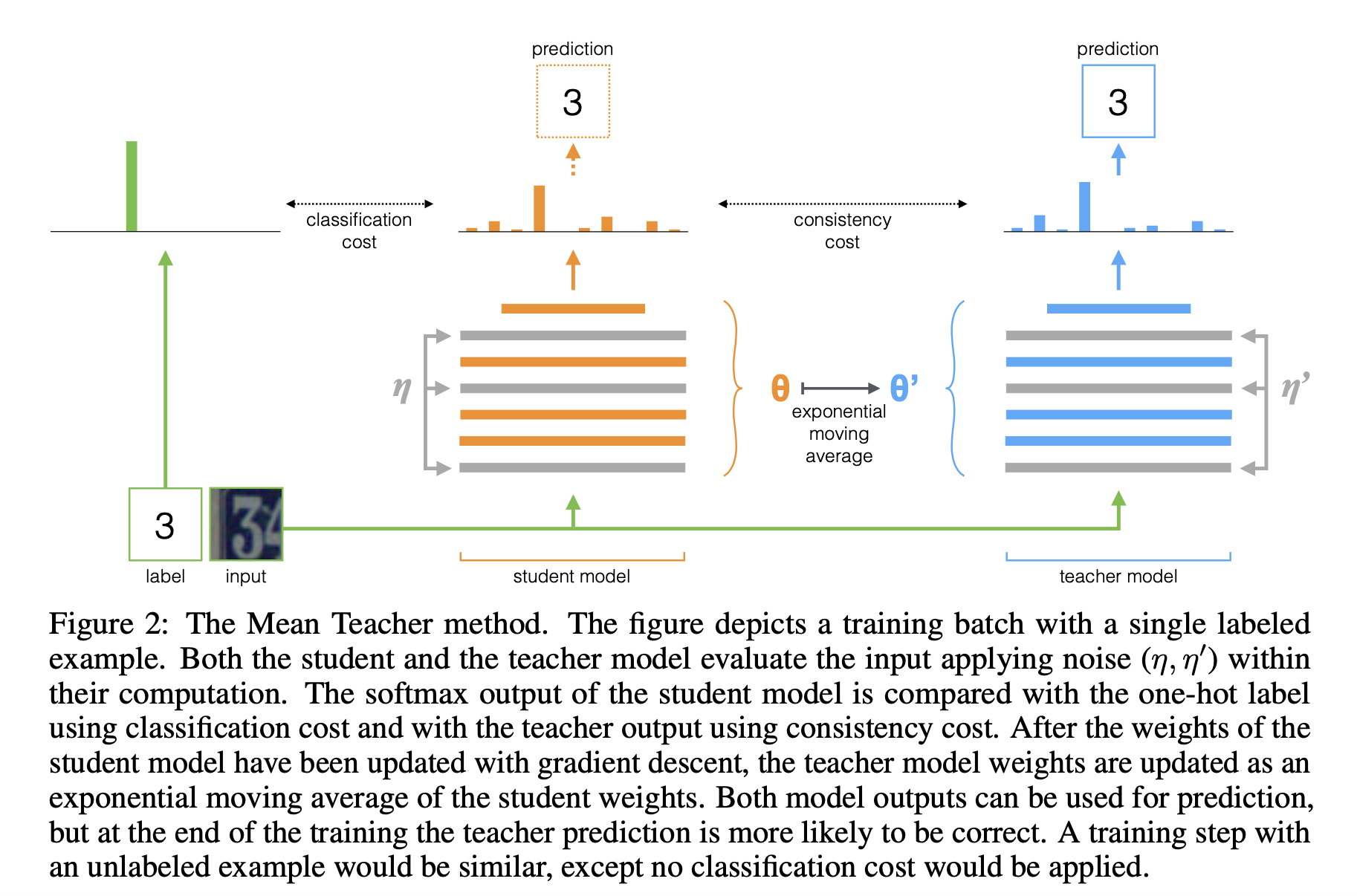
개요 논문 링크: https://arxiv.org/pdf/2308.06777.pdf (Shrinking Class Space for Enhanced Certainty in Semi-Supervised Learning) 깃헙: https://github.com/LiheYoung/ShrinkMatch 이전 글: [논문 리뷰] FixMatch [논문 리뷰] ReMixMatch 요약: (classification 관련) semi-supervised learning 에서 SOTA를 찍은 최신 논문이다. FixMatch같은 방식들은 unlabeled data를 활용할 때 pseudo-label의 confidence가 낮으면 버리는 방식으로 학습을 하는데, 이렇게 하면 unlabeled data를 충분히 활용할 수가..