728x90
728x90
개요
논문 링크:https://arxiv.org/abs/1904.12848
이전 글:
Data augmentation을 잘하는 것이 (semi-supervised training에서) consistency training에 중요하다고 보인 논문 중 하나다. Supervised training에서 augmentation을 잘하는 방법이 발전되어 왔는데, semi-supervised training에 이러한 augmentation 방법들을 적용하면 좋은 결과를 얻을 수 있다는 것이 핵심이다: " To emphasize the use of better data augmentation in consistency training, we name our method Unsupervised Data Augmentation or UDA." Classification task에 초첨을 둔다.
방법
- x: input
- y*: ground truth prediction target
- \( p_\theta (y|x)\): input x로 y* 를 구하는 것이 학습 목표
- \( \theta\): 모델 parameter
- \( p_L(x)\): labeled example의 distribution
- \( p_U(x)\): unlabeled example의 distribution
- f*: 완벽한 classifier
- \( \hat{x}\) x를 augment해준 distribution. \( \hat{x}\)는 \( q(\hat{x}|x)\)에서 샘플링한다 (q는 x를 augmentation한 distribution).
- augmentation은 이미지의 label을 보존해줘야한다
- UDA 학습 방식은 Figure 1이 잘 설명해 준다
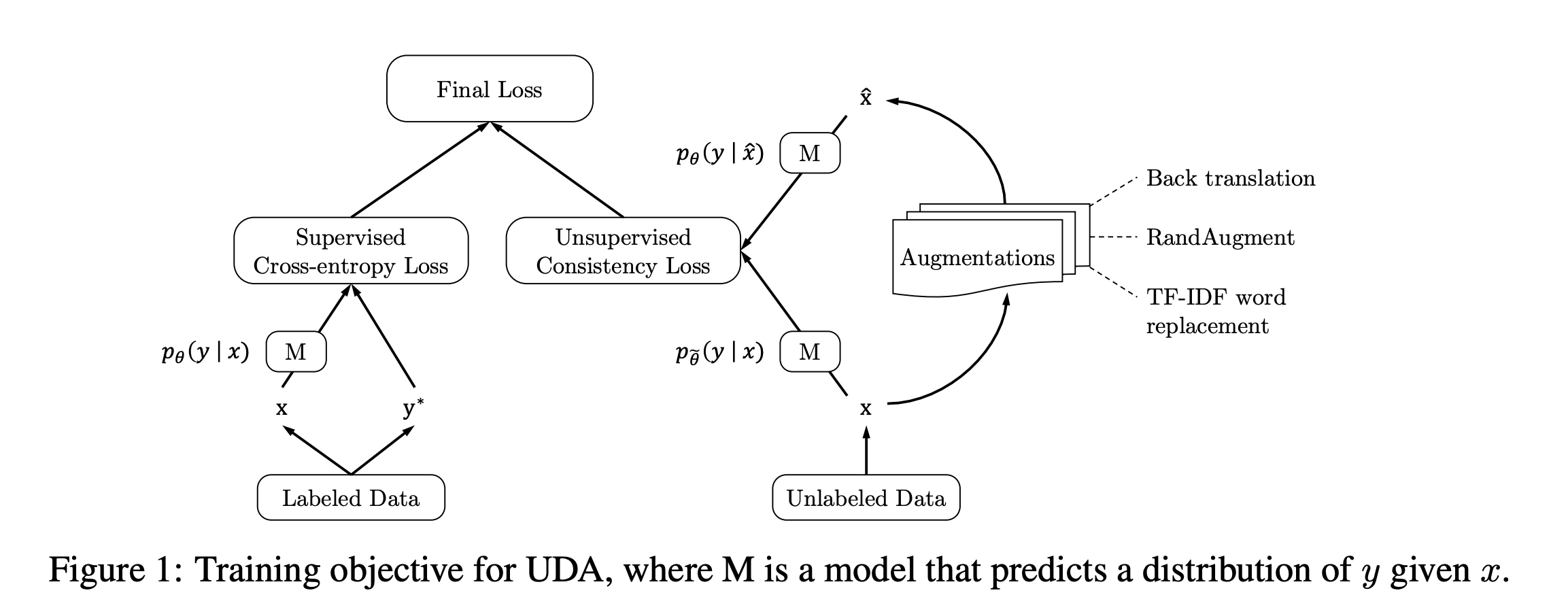
- Loss:
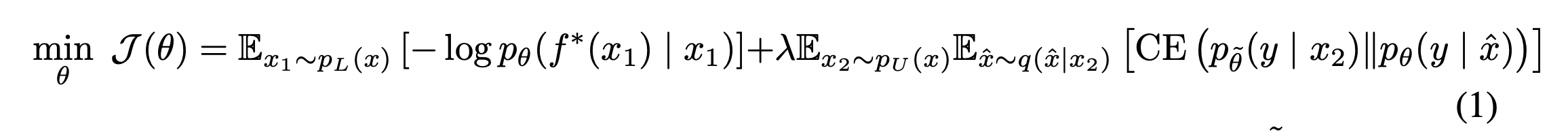
- CE: cross entropy, \(\tilde{\theta} \): \( \theta\)와 parameter 값은 같지만 parameter을 freeze했다는 뜻 (\(\tilde{\theta}\) 에 대해서 gradient descent를 하지 않겠다는 뜻)
- consistency loss (식 1에서 2번째 항)에 더 큰 batch size를 사용
- 핵심은 consistency loss에 강한 augmentation을 사용한다는 것
- image classification에서는 RandAugment (https://arxiv.org/abs/1909.13719) 사용
- text classification에서는 back translation (https://arxiv.org/abs/1511.06709), TF-IDF word replacement 사용. TF-IDF word replacement는 UDA에서 제시한 방법: "augmentation method that replaces uninformative words with low TF-IDF scores while keeping those with high TF-IDF values."
- 참고: image classification에서는 labeled example에 대해서 \( p_\theta (y|x)\)를 계산할 때 cropping, flipping 사용. Unlabeled data에 대해서 \( p_{\tilde{\theta}} (y|x)\)를 계산할 때도 동일한 augmentation 사용.
추가적인 트릭들
- Confidence-based masking: confidence가 낮은 샘플에 대해서는 consistency loss 를 계산하지 않는다. 구체적으로 가장 높게 에측된 class probability 가 threshold \( \beta\)보다 낮은 경우 무시한다. \( \beta\) 값은 CIFAR-10에 대해서 0.8, SVHN에 대해서 0.5 사용.
- Sharpening predictions: pseudo label이 low entropy를 갖는 것이 도움 된다는 것은 잘 알려져 있다. 다음과 같이 pseudolabel을 sharpen한다 (\( \tau = 0.4\) 사용)

- Domain-relevance data filtering: in-domain data (labeled data)에 대해서 학습된 모델을 기반으로 out-of-domain data (unlabeled data)에 prediction을 하고, 충분히 confident한 example들만 consistency training에 사용. 이렇게 하는 이유는 쉽게 collect할 수 있는 unlabeled data는 labeled data와 data distribution과 다를 수 있기 때문에 직접 사용하면 성능 저하가 있을 수 있기 때문이라고 한다.
결과
- supervised training에 도움이 되는 augmentation은 semi-supervised training에도 도움이 되는 경향이 있다고 한다. Table 1,2에 결과가 정리되어 있다.

- 다른 다양한 실험들은 논문 참고
728x90
728x90
'논문 리뷰 > semi-supervised learning' 카테고리의 다른 글
| [논문 리뷰] ShrinkMatch (0) | 2023.08.24 |
|---|---|
| [논문 리뷰] FixMatch (0) | 2023.06.04 |
| [논문 리뷰] ReMixMatch (0) | 2023.04.06 |
| [논문 리뷰] Virtual Adversarial Training (0) | 2023.04.02 |
| [논문 리뷰] MixMatch (0) | 2023.03.22 |