728x90
728x90
개요
논문 링크: https://arxiv.org/abs/2001.07685
이전 글:
semi-supervised learning 논문. 복잡해지는 semi-supervised training방법들에서 중요한 요소들을 잘 통합해서 간단하지만 성능이 좋은 방법이라고 저자들은 설명한다. 간단히 요약하자면 consistency regularization과 pseudo-labeling을 같이 사용하는 semi-supervised training 방법이라고 이해하면 된다.
방법
Notation
- L: 데이터셋에 class 수
- B: batch size (labeled data)
- \( \mathcal{X} = \{ (x_b,p_b): b \in (1,...,B) \}\): labeled data의 batch
- \( x_b\): training example
- \( p_b\): one-hot labels
- \( \mathcal{U} = \{ u_b: b \in (1,...,B) : b \in (1,...,\mu B)\}\): unlabeled data의 batch
- \(\mu \)는 labeled /unlabeled data 비율을 조절하는 hyperparameter
- \( p_m(y|x)\): 모델의 class probability 예측 값
- H(p,q): cross entropy
- \( \mathcal{A}(\cdot)\): strong data augmentation
- \( \alpha(\cdot)\): weak data augmentation
Consistency regularization
- unlabeled data를 활용하는 방법 중 하나
- 기본적인 형태는 unlabeled data에 weak augmentation을 두 번 (다르게) 줘서 서로 예측 값이 같도록 하는 방법이다:
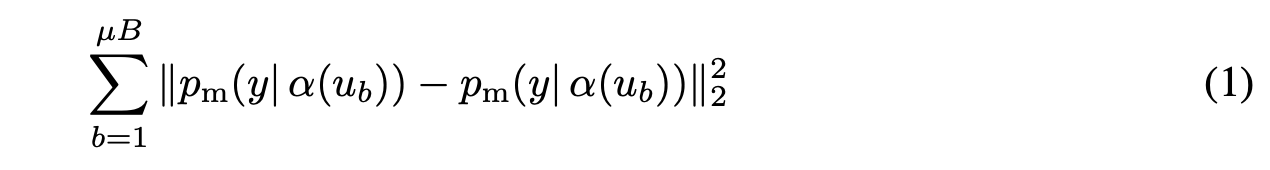
Pseudo-labeling
- unlabeled data를 활용하는 방법 중 하나
- 기본적인 형태는 unlabeled data에 대해서 모델이 예측을 하고 (q=모델 예측 값), 예측 confidence가(예측 class 확률 중 가장 높은 값) threshold \( \tau\)보다 높은 경우, 예측 확률 즁 가장 높은 class \(\hat{q} \)를 실제 label로 간주하고 cross entropy loss를 사용하는 방법:

FixMatch
- loss = \( \ell_s + \lambda_u \ell_u\)
- \( \ell_s\)는 supervised loss. labeled example에 weak augmentation을 하고 ground truth label과 cross entropy loss로 구현한다

- \( \ell_u\)는 FixMatch에서 사용하는 unlabeled example에 대한 loss. Weak augmentation \( \alpha \) 를 사용한 label에 대해서 모델이 예측하는 class confidence가 \( \tau\)보다 높은 경우, 가장 높은 확률을 갖는 class를 ground truth로 사용한다 (pseudo-label 방법과 같이). 여기서 중요한 점은 pseudo-label과 다르게 강한 augmentation \( \mathcal{A}\)를 준 unlabeled data와 cross entropy를 계산한다는 것이다 (consistency regularization 효과).
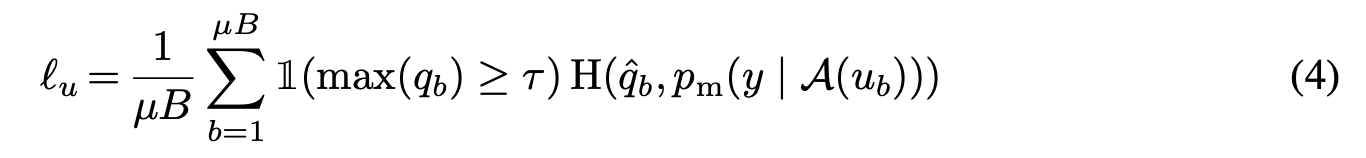
- \( \lambda_u\): hyperparameter
- 정리하면 다음과 같다:

사용된 augmentation 추가 설명
- weak augmentation: random horizontal flip (50%확률, 하지만 SVHN에서는 flip 사용하지 않음) + random translation (이미지 사이즈의 12.5%, 가로 세로 방향)
- strong augmentation: RandAugment + Cutout 또는 AutoAugment + Cutout. 보통 이 두 가지 augmentation strategy에 성능 차이는 없다 (labeled example이 극단적으로 적으면 차이가 있다고 한다)
- 주의: 여기서 저자들이 말하는 RandAugment는 원래 버전과 조금 다르기 때문에 참고: "We found that sampling a random magnitude from a pre-defined range at each training step (instead of using a fixed global value) works better for semi-supervised training, similar to what is used in UDA [54]." (디테일은 논문의 Appendix 참고)
추가적인 중요한 factor들
- SGD의 weight decay에 sensitive하다고 한다 (밑에 그림 참고)
- Adam optimizer보다 SGD를 사용했을 때 더 좋은 결과를 얻었다고 한다

- cosine learning rate decay 사용: \( lr = \eta \cos \frac{7\pi k}{16K}\), \( \eta\): initial learning rate \( k\): current training step, \( K\): total training steps
- 학습 도중 모델 paramter의 exponential moving average를 구해서 마지막에 결과를 도출한다
- 사용한 hyperparameter 차트 (참고로 \( K = 2^{20}\) 사용, \( \beta\)는 SGD의 momentum이다):

결과
- 다른 방법론들과 비교는 table 2 참고. 다양한 실험들은 논문 참고.

728x90
728x90
'논문 리뷰 > semi-supervised learning' 카테고리의 다른 글
| [논문 리뷰] ShrinkMatch (0) | 2023.08.24 |
|---|---|
| [논문 리뷰] Unsupervised Data Augmentation for Consistency Training (0) | 2023.06.03 |
| [논문 리뷰] ReMixMatch (0) | 2023.04.06 |
| [논문 리뷰] Virtual Adversarial Training (0) | 2023.04.02 |
| [논문 리뷰] MixMatch (0) | 2023.03.22 |