728x90
728x90
논문 링크: http://kunzhou.net/2012/facewarehouse-tr.pdf
- 표정 의미가 있는 3DMM을 만든 논문이다. PCA를 활용하는 방법과 대조적으로 이렇게 얻은 3DMM의 표정들은 해석이 가능하다
- 3DMM이란 다양한 사람의 얼굴의 모양과 표정을 나타낼 수 있는 모델이다. FaceWarehouse는 linear한 모델이다.
- linear 3DMM: \( V_{ijk}\)가 3DMM이라면 특정 사람의 얼굴은 \( F_{i}=\sum_{jk}V_{ijk}w^{id}_j w^{exp}_{k}\)로 나타낼 수 있다. 여기서 i는 face mesh의 vertex index이고, j는 identity index에 해당하고 k는 expression index에 해당한다. \( w^{id}\)는 특정 사람의 얼굴을 표현하는 vector이고, \( w^{exp}\)는 사람의 표정을 표현하는 vector이다.
- 3DMM에 대한 자세한 리뷰는 https://arxiv.org/abs/1909.01815 참고
- PCA를 사용한 대표적인 3DMM은 "A Morphable Model For The Synthesis Of 3D Faces" 논문 참고
- Microsoft Kinect 카메라를 (depth camera) 사용해서 얼굴에 대한 3D 정보를 얻고, 3D 정보에 mesh를 fitting해준다. 이 3D mesh를 기반으로 3DMM을 만든다.
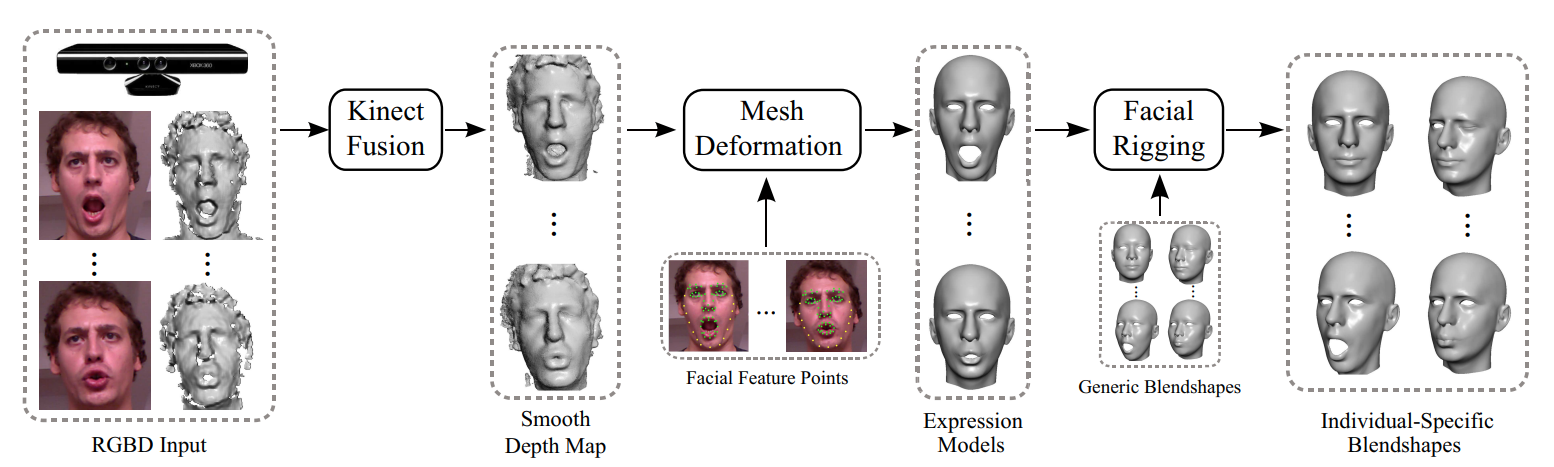
데이터 수집
- 목표: 사람 얼굴에 대한 3D 데이터 수집 (사람의 얼굴 이미지와 이에 대응되는 depth map)
- 장비: Kinect sytem
- 표정: 20개 무표정(neutral expression) 1개 + 다양한 표정 19개에 대한 3D 데이터를 수집한다
- 19개의 표정: mouth stretch, smile, brow lower, brow raiser, anger, jaw left, jaw right, jaw forward, mouth left, mouth right, dimpler, chin raiser, lip puckerer, lip funneler, sadness, lip roll, grin, cheek blowing and eyes closed
- 각 표정마다 template mesh를 먼저 만들어둔다
- 표정을 짓는 사람에게 20개의 template mesh (\( G_0, G_1, ..., G_{19}\))를 보여주고 비슷한 표정을 짓게 한다
- 각 표정을 지은 상태에서 고개를 살살 돌려서 비디오 데이터를 수집한다
- 3D data의 noise를 줄이기 위해서, 고개를 돌리는 데이터들을 기반으로 Kinect Fusion algorithm을 사용해서 각 표정에 대한 3D 데이터 수집한다 (noise가 적은 얼굴의 depth 정보를 수집한다는 의미)
- Fig. 1에서 RGBD input -> Smooth Depth Map 참고
데이터 후처리
- 목표: 데이터 수집 단계에서 얻은 3D 정보를 mesh로 바꾼다 (150명, 각 사람당 20개의 표정). 이렇게 얻은 20개의 mesh를 기반으로 47개의 FACS 기반 표정에 대한 mesh를 얻는다 (47개 중 1개는 무표정).
- 우선 각 표정마다 Active Shape Model을 사용해서 74개의 feature point를 찾는다
- 여기서 feature point는 이미지에서 중요한 점들의 위치를 의미. 밑에 이미지 참고.

- 참고로 여기서 depth map을 사용해서 각 feature point의 3D 위치를 알 수 있다. 이렇게 얻은 정보를 기반으로 mesh를 fitting한다
- mesh fitting할 때 neutral expression과 다양한 표정들은 다르게 취급한다.
Neutral expression
- morphable face model을 사용해서 3D 데이터에 대응되는 initial mesh를 얻고, 추가적으로 refine하는 방식으로 neutral face에 대응되는 mesh를 얻는다.
- Blanz, Vetter의 morphable face 모델을 활용한다. V, F, \( \alpha\)는 다음과 같이 정의된다.

- 이것을 하기 위해서 다음과 같은 energy (loss function)을 최소화한다:
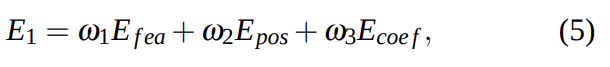
- 여기서 \( \omega_1 = 2, \omega_2 = 0.5, \omega_3 = 1\)
- 각 항들의 의미는 다음과 같다.
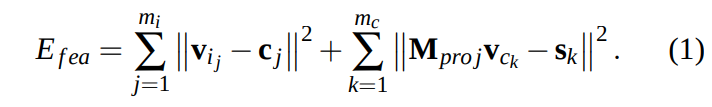
- \( E_{fea}\) 는 3D 데이터의 feature point와 Blanz & Vetter에서 사용하는 mesh에서 대응되는 vertex의 위치들을 맞춰주는 역할을 한다. 얼굴의 눈코입 같은 곳에 위치한 feature은 첫 번째 항, 얼굴의 boundary (contour)에 위치한 feature들은 두 번째 항에서 취급한다.
- 첫 번째 항:
- \( m_i\) 는 눈썹, 눈, 코, 입에 위치하는 feature point의 수를 의미한다 (위에 feature point 이미지 참고)
- \( c_j\): j번째 feature point의 3D 위치
- \( v_{i_j}\): j번째 feature point에 대응되는 mesh V의 vertex 위치 (위에 언급한 Blanz Vetter에서 사용하는 mesh V). Blanz & Vetter에서 사용한 평균 얼굴에서 사람이 vertex picking을 해서 대응되는 점을 찾는다.
- 두 번째 항:
- \( m_c\) 는 얼굴 boundary에 위치하는 feature point들을 의미한다 (위에 feature point 이미지 참고)
- \( s_k\)는 이미지에서 2D feature point 들을 의미한다.
- \( v_{c_k}\)는 V에서 대응되는 vertex 위치. 이들 같은 경우 사람이 고르기 어렵다.
- \( M_{proj}\): 카메라의 projection matrix
- \( s_k\)는 Active Shape Model로 얻지만 이에 대응되는 \( v_{c_k}\)는 다음과 같이 찾아야 한다

- \( E_{pos}\)는 depth map에 대한 energy term:

- 얼굴 shape 정보가 Blanz & Vetter에서 얻은 데이터 distribution과 너무 차이 나지 않게 하기 위해서 다음과 같은 regularization term을 추가한다:
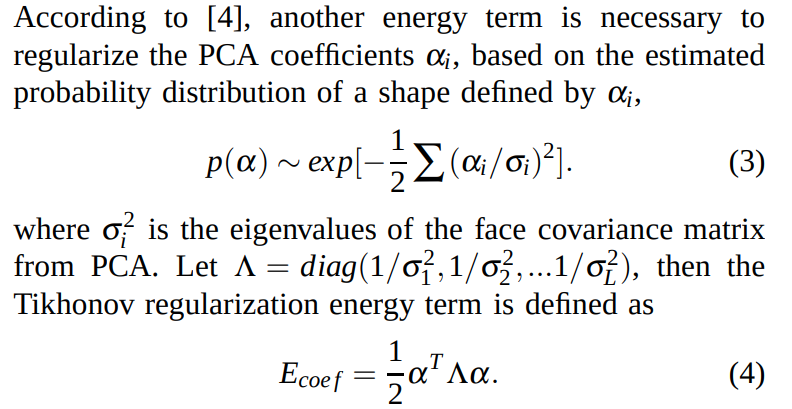
- 식 (5)는 least squares 문제이고, 여러 iteration을 거쳐서 이뤄진다. 여러 iteration이 필요한 이유는 식 (1), (2)를 계속해줘야 하기 때문이다: 각 iteration 사이에 식 (1)에서 \( s_k\)에 대응되는 \( v_{c_k}\)를 다시 구해야 하고, 식 (2)에서 \( v_{d_j}\)에 대응되는 \( p_j\)도 업데이트해야 한다.
- 식 (5)를 통해서 initial mesh를 구하게 된다. 이 initial mesh를 추가적으로 deform해서 3D 데이터에 대응되는 정확한 mesh를 얻는다:
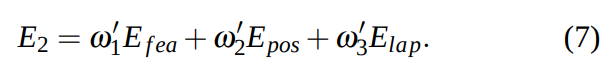
- 여기서 \( E_{lap}\)은 regularization term이다
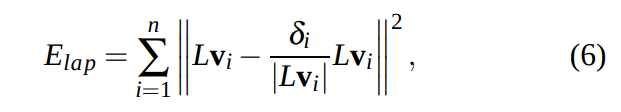
- L: laplacian (cotangent 사용한 laplacian, Implicit fairing of irregular meshes using diffusion and curvature flow 논문 참고)
- \(\omega_1'=0.5, \omega_2'=\omega_3'=1\)
- “Subspace gradient domain mesh deformation" 논문에서 사용한 inexact Gauss Neuton method로 최소화했다고 한다
- 이렇게 얻은 mesh를 \( S_0\)라고 하자
다른 표정들
데이터 수집할 때 사용했던 template mesh \( G_i\)를 활용해서 얻는다
Deformation transfer을 사용해서 neutral expression에서 얻은 \( S_0\)에 template mesh의 deformation을 입혀줘서 initial mesh를 얻는다
- "Deformation transfer for triangle meshes" 논문에서 사용한 deformation transfer 사용
- \( G_0 \rightarrow G_i\)의 deformation을 \( S_0\)에 입혀준다는 의미
이렇게 얻은 initial mesh 기반으로 neutral face에서 한 것처럼 refine해준다.
FACS 기반 표정의 mesh
"Example-based facial rigging"에서 제시한 방법을 사용해서 20개의 표정에 대한 mesh를 토대로 47개의 표정에 대한 mesh를 얻는다 (이때 1개는 무표정)
3DMM 얻는 방법
위에서 얻은 mesh가 있으면 간단하다. 모든 mesh를 다음과 같이 concatenate한다: 11K vertices x 150 identities x 47 expressions
- vertex 수가 11,000
- 150명에 대해서 얻었기 때문에 150 identities
- 47개의 표정에 대한 mesh를 얻었기 때문에 47 expressions
2번째 dimension (150)에 대해서 PCA를 해서 필요한 수의 principle component만 keep하면 끝.
728x90
728x90
'논문 리뷰 > face' 카테고리의 다른 글
| [논문 리뷰] Few-shot Geometry-Aware Keypoint Localization (0) | 2023.08.10 |
|---|---|
| [논문 리뷰] HiFace: High-Fidelity 3D Face Reconstruction byLearning Static and Dynamic Details (0) | 2023.08.01 |
| [논문 리뷰] Facial Retargeting with Automatic Range of Motion Alignment (0) | 2023.06.12 |
| [논문 리뷰] FaceScape (0) | 2023.05.17 |
| [논문 리뷰] FLAME (0) | 2023.04.30 |