개요
논문 링크: https://arxiv.org/abs/2004.10934
이전 글: [논문 리뷰] YOLO-v3
YOLOv3에 다양한 기법들을 추가해서 성능을 높인 논문이다. 여기서 성능은 단순히 AP (average precision)을 높이는 것보다 속도 대비 AP가 좋은 것을 뜻한다:

이것을 이루기 위해서 정말 많은 기법들이 추가되었다:

이번 포스트에는 이것들을 하나하나 뜯어보려고 합니다. 각각 길기 때문에 접은 글로 처리했습니다.
방법
1. Detection Model
Backbone: 이미지를 처음 프로세싱하는 neural net 부분
Neck: neural net feature들로 FPN같이 다시 프로세싱하는 부분
Head: neck의 output으로 prediction하는 부분
다음 그림이 설명해준다. YOLO 같은 경우 이미지에서부터 바로 bbos를 예측하기 때문에 one-stage detector에 해당한다 (two-stage detector은 이 포스트에서 다루지 않겠다).

여기서 언급한 모든 모델들을 다루기에는 너무 방대하기 때문에 직접 사용하는 부분만 다루겠다.
CSPDarknet53 (backbone)
Darknet53은 YOLO-v2에서 사용했던 Darknet19에 residual connection을 추가하고 사이즈를 키운 모델이라고 생각하면 된다.
CSPDarknet53 같은 경우 cross stage partial network를 Darknet에 적용한 구조다.
우선 Densenet부터 살펴보자. 기본적으로 Densenet은 dense block을 사용한 구조다.

x를 feature, w를 filter weight라고 하자. 식으로 풀어쓰면 dense block 구조는 다음과 같다.

weight update rule은 식을 보고 곰곰이 생각해 보면 다음과 같이 된다 (자세히 수식으로 적으면 좀 더럽기는 하다). 여기서 gi는 i번째 layer까지 propagate 되는 gradient를 나타낸다.

여기서 포인트는 gi가 다른 weight를 업데이트할 때 여러 번 재사용된다는 것이다. 따라서 여러 layer들이 같은 gradient 정보를 학습을 하게 된다.
반면 CSPDensenet에서는 우선 x0를 x0=[x0', x0'']로 channel 방향으로 쪼갠다. x0'는 DenseNet처럼 (partial) dense block를 통과하고, convolution을 통해서 xT에서 x0''와 합류해서 (concatenate) xT를 만든다 (partial transition layer). xT는 또 다른 convolution을 통과해서 xU가 된다.

식으로 정리하면 다음과 같다:

여기서 x'와 x''를 쪼갰기 때문에 DenseNet처럼 gradient가 재사용되는 것이 적지만 (gradient를 계산할 때 x', x'' 쪽으로 gradient flow path가 나눠진다), feature reuse 하는 철학은 유지된다. 계산도 더 효율적으로 하게 되는 효과도 있다. 더 자세한 내용은 CSPNet 논문 참고
Darknet53에 적용하면 다음 구조가 나온다 (Mish는 뒤에 설명하겠다)

이 모델을 선정한 이유: detection 문제에서는 input size가 커야 하고 (high resolution이 필요), layer 수가 많아야 하고 (receptive field size가 커야 큰 물체를 찾을 수 있기 때문), model parameter이 많아야 한다 (여러 물체를 찾기 위해서 capacity가 커야 한다). 이런 수치들을 정리해 보면 CSPDarknet53이 좋다 (실험적으로도 좋다고 한다).

SPP (neck)
원래 SPP (spatial pyramid pooling)는 다양한 input size에 대해서 convolutional neural net을 사용할 수 있게 하려고 디자인한 구조다.

보다시피 feature dimension이 C,H,W일 때:
- Cx1x1로 pooling
- Cx2x2로 pooling
- Cx4x4로 pooling
하고 1차원으로 flattening해서 feature을 만든다. 이렇게 합친 feature은 convolutional layer에서 나오는 feature dimension에 관계없이 고정된 feature dimension을 갖게 되기 때문이 neural network가 input image 사이즈와 무관하게 사용할 수 있게 된다.
여기서 문제점은 이렇게 프로세싱된 feature은 1차원이라는 것이다. 따라서 다음과 같이 약간 변형해서 사용한다.

보다시피 backbone output을 kxk convolution (k=1,3,9,13)을 통과시켜서 concatenate 해준다. receptive field도 증가해 주면서, 다양한 스캐일에서 이미지를 보도록 하는 효과가 있다.
PAN (neck)
FPN (feature pyramid network)를 개선한 방법이다. 밑에 그림에서 (a)는 FPN에 해당되고, (b)는 bottom up pathway를 추가한 것을 보여준다. (a) + (b)까지 한 것이 YOLO-v4에서 사용한 PAN에 해당된다. (c), (d), (e)는 YOLO-v4에서 무시해도 된다.

원래 PAN에서는 (a)처럼 bottom-up pathway에 addition을 사용했다
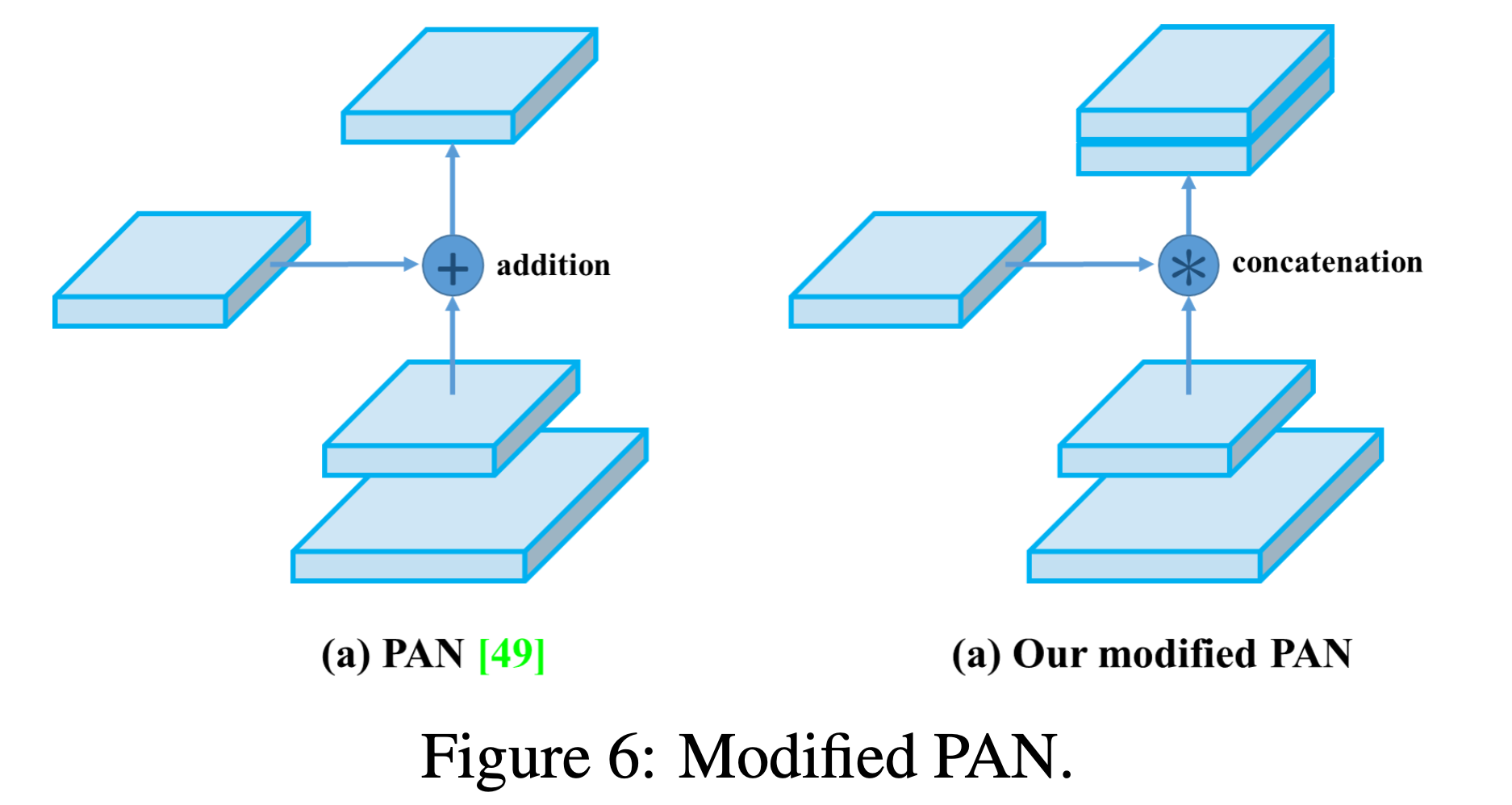
여기서 \( \oplus \)는 elementwise addition을 의미하는데, YOLO-v4에서는 (b)처럼 addition 대신 concatenation을 사용했다. 참고로 N_{i}와 P_{i+1}를 합치기 위해서 3x3 convolution with stride 2를 사용해서 N_{i}의 spatial dimension을 줄여준다. 그리고 합친 후 다시 3x3 convolution을 통과시켜 준다. 원래 논문에서는 모든 convolution 후 ReLU를 사용했다.
MiWRC
MiWRC (multi-input weighted residual connection)은 여러 input layer들을 섞어줄 때 weight를 다르게 줘서 섞는 방법이다. 원래 BiFPN에서 사용했다

(d)에서 bottom-up pathway를 보면 한 layer은 여러 layer들이 더해져서 만들어지는데, 이런 layer들의 중요도는 일반적으로 다를 수 있다. 따라서 다음과 같이 더해준다 (w는 weight, I는 layer에 들어오는 여러 layer들)

자세한 내용은 EfficientDet 논문 참고. YOLO-v4에서 backbone에 사용했다고 하지만 구체적으로 어떻게 사용했는지는 못 찾았다.
SAM
SAM(Spatial attention module)은 convolution에 attention mechanism을 넣는 방법 중 하나다.
원래 SAM은 convolutional block에서 나온 feature (CxHxW)을 가지고 channel 방향으로 max pooling 한 feature (1xHxW), average pooling 한 feature (1xHxW)를 concatenate 해서 7x7 convolution & sigmoid를 통과시킨다. 이 결과 (1xHxW)를 원래 feature map과 곱해서 (channel 방향으로 복붙 해서 CxHxW로 바꾸고 elementwise product) 공간 방향으로 attention을 주는 방법이다 (밑에 그림 참고)
YOLO-v4에서는 Max-Pooling/Average-Pooling 대신 그냥 convolution을 한다.

CmBN
mini-batch에 많은 이미지가 없으니까 Batch Norm에 batch에 대한 통계가 부정확하다. 이것을 해결하기 위한 방법 중 하나인데, 정확한 설명을 찾을 수 없었다. CBN같은 경우 이전 iteration (training step)들의 mean & variance를 사용해서 현제 step에 대해서 BN에 필요한 mean & variance를 보완하는 방법이다. CmBN은 이것을 training step에 대해서가 아니라 batch 안에 있는 mini-batch에 대해서 했다고 하는데, 정확히 어떤 의미인지 파악이 안 된다.

Mish activation
ReLU 대신 Mish를 사용했다고 한다. Mish는 다음과 같이 생긴 함수다 (a): 함수, (b) 미분

함수 정의는 다음과 같다:

자기 자신과(x) non-linear function을 통과시킨 값 (tanh(ln(1+e^x)))을 곱해준다. 음수일 때도 0이 아니고, 양수 쪽으로는 unbounded 되어있어서 saturation 현상이 없고 (sigmoid같이 bounded x), 음수 쪽으로는 bounded 되어있어서 regularizing효과가 있다고 한다. smooth 해서 미분 가능. ReLU보다 좋은 성능을 보이는 실험들이 많았다고 한다.
종합하면 다음과 같은 구조가 나온다.

2. Augmentation, regularization
CutMix, Mosaic
이미지들을 잘라서 붙이는 방법들이다.
CutMix는 두 개의 이미지만 섞지만 Mosaic은 (새로 제시한 방법) 4개의 이미지를 잘라서 섞는다. 물체의 bbox가 너무 손상되지 않는 것들만 사용한다.
https://www.youtube.com/watch?v=V6uj-eGmE7g&t=618s 참고.


class label smoothing
간단한 예로 class label을 [1,0,0]로 사용하지 않고 [0.9,0.05,0.05]를 사용하는 방법. (https://papers.nips.cc/paper_files/paper/2019/hash/f1748d6b0fd9d439f71450117eba2725-Abstract.html 참고)
Dropblock
Dropout 같은 경우 fully connected layer에는 좋은 regularization 효과가 있지만 convolutional net에는 그렇게 좋지 않다 (DropBlock 논문: "This lack of success of dropout for convolutional layers is perhaps due to the fact that activation units in convolutional layers are spatially correlated so information can still flow through convolutional networks despite dropout."). DropBlock 같은 경우 밑에 그림처럼 붙어있는 feature map을 통째로 마스킹해준다. (dropout은 랜덤 하게 feature들을 마스킹; dropblock은 옆에 붙어있는 feature들을 마스킹)

Self-adversarial training
Adversarial training을 알면 쉽게 이해할 수 있다. 물체가 없다고 착각하도록 이미지를 바꿔주고 (adversarial attack), 이 이미지에 대해서 detection을 하도록 학습하는 방법이다. 구체적인 implementation에 대해서는 잘 모르겠다 (아마도 Goodfellow 방식을 사용하지 않았을까.https://arxiv.org/abs/1412.6572 )
3. Loss, 기타 등등
IoU loss: scale invariant하다. 밑에서 B는 bbox; B^gt는 ground truth bbox

하지만 overlap이 없으면 0이 된다. 해결하기 위해서 GIoU loss를 제안했다. 여기서 C는 B와 B^gt를 커버하는 최소 크기의 box.

하지만 B와 B^gt가 옆에 딱 붙어있으면 C-B U B^gt랑 같다 (검은색 dashed line이 B/B^gt, 빨간색이 C)

해결하기 위해 DIou Loss 추가 (\( \rho\)는 bbox 중심 b 사이 Euclidean distance), c는 B,B^gt를 커버하는 최소 사이즈의 박스의 대각선 거리
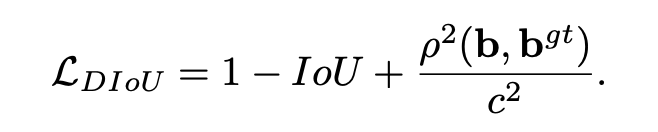
Aspect ratio (height vs width)를 고려하면 더 좋다:

다 합치면 CIoU loss:

여기서 \(\alpha\)는 trade-off parameter

IoU가 높을 때 aspect ratio를 더 많이 고려하겠다는 뜻.
Grid sensitivity
이해하기 어렵지는 않다: \( b_x = \sigma(t_x)+c_x\)같은 식에서는 \(b_x\)가 c_x에서 c_x+1사이만 될 수 있고, 이 범위 밖의 값을 가질 수 없다. sigmoid 특성상 이 사이 값들을 균등하게 취급하지 않는다. 1.0 이상 값을 곱해서 해결했다고 한다.

DIoU NMS
Non maximal suppression은 confidence가 가장 높은 bbox와 겹치는 (같은 class의) bbox들을 제거해서 너무 많은 bbox가 예측되지 않게 하는 방법이다. 여기서 보통 IOU를 사용하는데 대신 DIoU를 사용하는 방법이다 (DIoU는 위에 CIoU loss 참고)

Using multiple anchors for a single ground truth (threshold보다 큰 anchor 다 사용해서 학습), Cosine annealing scheduler, Optimal hyperparameters, Random training shapes은 어렵지 않기 때문에 상세한 설명 스킵.
learning rate, hyperparameter 등등은 실험할 때는 알아야하지만 논문을 이해하는데는 큰 도움이 안된다고 생각되서 다루지 않았습니다. 관심 있으면 논문 참고해주세요.
자세한 실험 결과도 관심 있으면 논문 참고해주세요.
참고 자료:
https://arxiv.org/abs/1911.11929
https://www.mdpi.com/2072-4292/13/10/1995
https://www.mathworks.com/help/vision/ug/getting-started-with-yolo-v4.html
https://arxiv.org/abs/1803.01534
https://medium.com/visionwizard/yolov4-version-2-bag-of-specials-fab1032b7fa0
https://arxiv.org/abs/1406.4729
https://arxiv.org/abs/1807.06521
https://arxiv.org/pdf/1911.09070.pdf
https://arxiv.org/abs/1908.08681
https://arxiv.org/abs/1810.12890
https://arxiv.org/abs/1911.08287
YOLO-v5에서는 이렇게 복잡하지 않다고 한다:
'논문 리뷰 > object detection' 카테고리의 다른 글
| [논문 리뷰] PP-YOLO v1 (+v2) (3) | 2023.05.26 |
|---|---|
| YOLOv5 정리 (2) | 2023.05.19 |
| [논문 리뷰] YOLOv3 (0) | 2023.02.22 |
| [논문 리뷰] YOLOv2 (0) | 2023.01.31 |
| [논문 리뷰] YOLOv1 (0) | 2023.01.24 |