728x90
728x90
PP-YOLO v1
개요
EfficientDet와 YOLO-v4 조금 이후 나온 논문. FPS 대비 성능이 더 좋다고 한다.

참고하면 좋은 글:
방법
YOLO-v3를 더 좋게 하는 방법들
Architecture
요약본은 밑에 그림 참고
Backbone: ResNet50-vd-dcn
- vd는 정확히 어떤 버전을 지칭하는지 잘 모르겠다 (찾아보면 "Bag of Tricks for Image Classification with Convolutional Neural Networks"에서 나오는 ResNet-50-D인 것 같아 보이지만 잘 모르겠다)
- dcn: deformable convolution network. 너무 많이 추가하면 속도 저하가 있기 때문에 마지막 layer에 3x3 convolution들을 deformable convolution으로 교체하였다
- 단순 DarkNet-53를 ResNet50-vd로 교체하면 성능이 그렇게 좋지는 않지만 deformable convolution을 추가하면 좋은 결과를 얻었다고 한다.
Neck: 기본적인 Feature pyramid network
- P_3,P_4,P_5 사용. 각 P_l의 resolution은 \( \frac{W}{2^l} \times \frac{H}{2^l}\), W, H = 이미지의 width, height
Head: YOLOv3와 detection head 사용
- 3x3 convolution -> 1x1 convolution으로 예측
- 마지막 output channel: 3(K+5). 여기서 K = number of classes, 3 = anchor 수, 5 = bbox 위치 + objectness
Loss
- classification: cross entropy loss
- bbox: L1 loss
- IoU loss (Tricks에 추가 설명)
- objectness loss: YOLO-v3와 동일한 loss (logistic regression task). bbox 안에 물체가 있는지 알려주는 score이다.

Tricks
저자들에 의하면 새로운 trick을 소개하는 논문은 아니고, 어떻게 잘 조합하는지 방법 제시가 목표라고 한다.
- Large batch size: 기존의 64 -> 192
- EMA: 학습 도중 모델 parameter을 exponential moving average해두고 학습이 끝난 후, inference할 때 EMA한 parameter을 사용. Weight EMA decay rate (lambda)= 0.9998.

- DropBlock: 밑에 그림처럼 feature map에서 완전 랜덤하게 drop out하지 않고 block들을 drop out하는 regularization 방법. Backbone에 추가하면 성능 저하가 있지만 feature pyramid에 추가하면 성능이 좋아졌다고 한다. 사용하는 구체적인 위치는 Figure 2에서 삼각형으로 표시되어 있다.

- IoU Loss: YOLO-v4같은 경우 bbox의 L1 Loss를 IoU loss로 교체하지만 여기서는 bbox같은 경우 L1 loss를 그대로 사용하였다. 대신 IoU를 따로 예측하고 IoU에 대해서 loss를 추가적으로 계산했다고 한다. CIoU loss, GIoU loss를 사용해도 별 차이가 없어서 기본적인 IoU loss를 사용했다고 한다.
- IoU Aware: YOLO-v3에서는 detection confidence = objectness x classification accuracy인데, 이렇게 계산하면 얼마나 bbox가 잘 잡혔는지 (localization) 잘 측정이 안된다. objectness x classification accuracy x IoU를 하면 localization도 고려가 되어서 더 좋다고 한다. IoU를 예측하는 branch를 추가하는데 cost는 거의 없다.
- Grid Sensitive: YOLO-v4에서도 다뤘던 문제다. YOLO-v3에서는 밑에 식 2,3을 사용해서 bbox의 center x,y를 찾는다. 하지만 sigmoid 특성상 grid point 근처에 bbox center이 있으면 예측하기 어려워진다. 그래서 식 4,5같이 바꿔주고 alpha=1.05를 사용했다고 한다
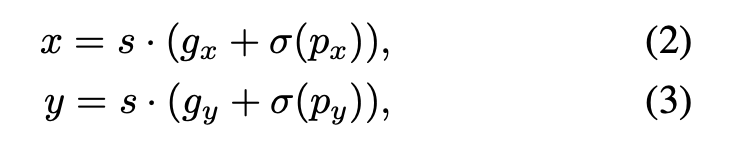
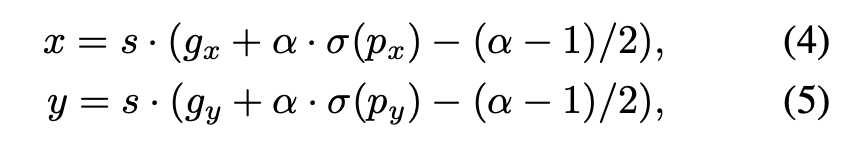
- Matrix NMS: NMS를 빠르게 하는 방법 중 하나 (https://arxiv.org/pdf/2003.10152v3.pdf)
- CoordConv: convolution network가 coordinate prediction에 그렇게 좋지는 않은 문제를 해결하는 트릭 중 하나. 이미지/feature에 (사이즈: H x W x C) x & y coordinate 위치 정보를 담은 이미지 채널을 추가해서 (H x W x (C+2)) 사용하는 방법이다. 밑에 그림을 보면 이해가 더 쉬울 것이다. 이렇게 하면 연산량이 높아지기 때문에 FPN과 detection head의 일부에만 에만 추가했다고 한다. Figure 2에서 다이아몬드 모양으로 CoordConv가 추가된 부분들을 표시하였다.

- SPP: YOLO-v4처럼 SPP (spatial pyramid pooling)을 사용. Figure 2에서 SPP를 사용한 부분이 별표로 표시되어 있다.
- better pre-training: 잘 학습된 ResNet50-vd를 사용했다고 한다
실험
실험 세팅

Ablation study

PP-YOLO v2
tech report에 가깝기 때문에 중요 아이디어만 정리해보겠다.
링크: https://arxiv.org/abs/2104.10419
성능 요약:

방법
- Architecture: (yolo v4처럼) FPN 대신 PAN (path aggragation network) 사용

- Mish activation 사용. YOLO-v4와 조금 다르게 detection neck에만 Mish activation 사용 (backbone은 잘 학습된 ImageNet pretrained model을 사용하기 위해서 변경하지 않음)
- 더 큰 input image size 사용 (batch size: 24 images/GPU -> 12 images/GPU, 가장 큰 이미지 사이즈는 608 -> 768). 이미지 사이즈는 [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768]에서 샘플 한다고 한다.
- IoU aware loss를 다음과 같이 수정

728x90
728x90
'논문 리뷰 > object detection' 카테고리의 다른 글
| [논문 리뷰] YOLOX (0) | 2023.06.03 |
|---|---|
| [논문 리뷰] EfficientDet (0) | 2023.05.28 |
| YOLOv5 정리 (2) | 2023.05.19 |
| [논문 리뷰] YOLOv4 (상세 리뷰) (0) | 2023.04.11 |
| [논문 리뷰] YOLOv3 (0) | 2023.02.22 |