개요
논문 링크: https://arxiv.org/abs/2107.08430
참고: [논문 리뷰] YOLO-v3
Object detection분야에서 anchor free detection (anchor box 사용하지 않는 방식), optimal label assignment (어떻게 효율적으로 GT를 anchor box/point에 할당하는가), NMS free (NMS를 사용 안 하는 방식) 방식들의 발전을 YOLO 시리즈에 추가한 논문. YOLO v4 & v5같은 경우 anchor을 사용하는 방식에 특화되어 있기 때문에 YOLO v3를 기반으로 설계하였다고 한다.
Figure 1을 보면 당시 YOLOX가 정말 효율적인 것을 알 수 있다

방법
학습 방식 (모든 모델에 적용)
- COCO train2017 데이터셋
- 5 epoch = warm-up, 총 300 epoch 학습
- learning rate = lr x batch size / 64 (linear scaling), lr = 0.01
- cosine learning rate schedule
- SGD, weight decay = 0.0005, momentum = 0.9
- batch size = 128 (8-GPU)
- input image size = 448 ~ 832, stride = 32 에서 샘플링 (448, 448+32, 448 + 32x2, ..., 832에서 랜덤하게 샘플링했다는 뜻)
YOLOv3 Baseline (원래 YOLOv3를 살짝 수정한 버전)
- Architecture: YOLOv3-SPP (DarkNet53 + SPP layer 사용)
- EMA weight update 사용 (학습 도중 parameter의 exponential moving average를 구해서 최종 모델에 EMA weight를 사용하는 방법, 코드를 보면 decay = 0.9998 사용)
- Loss: class, objectness는 BCE loss 사용, box regression branch는 IoU loss 사용
- Augmentation: Random horizontal flip, color jitter, multi-scale (위에 언급한 이미지 사이즈를 다양하게 샘플링하는 방법)만 사용
YOLOX에서 추가한 아이디어들
밑에서 설명할 트릭들의 효과:

Decoupled head
- 밑에 그림처럼 YOLO v3~v5에서 coupled head (class, objectness, box regression을 동일한 branch에서 예측하는 것)를 사용하지만 이것이 비효율적이다는 것은 여러 논문에서 검증되었다
- YOLOX에서는 branch를 나눠서 예측을 한다. 우선 1x1 convolution으로 channel dimension을 줄여주고, 2개의 branch로 나눈다 (3x3 convolution, 2 layer)
- decoupled head를 사용하면 모델이 수렴을 더 잘하고, end-to-end 학습을 할 때 핵심 역할을 한다고 한다.

Strong data augmentation
- Mosaic, MixUp 사용 (YOLO-v5 정리 참고)
- (특이하게도) 학습할 때 마지막 15 epoch에서는 사용하지 않는다
- Strong data augmentation을 사용하면 ImageNet pre-training은 도움 되지 않아서 (밑에 트릭들을 추가할 때) pre-trained 모델을 사용하지 않았다고 한다.
Anchor free
- Anchor의 단점: anchor 사이즈를 잘 설정해야하는 번거로움이 있고, 많은 연산량 (anchor마다 output이 필요함)을 요구한다. 잘 작동하려면 다음과 같은 트릭들이 필요하다
- anchor clustering (k-means clustering으로 anchor 사이즈 결정하는 방법, [논문 리뷰] YOLO-v2 참고)
- Grid sensitive (regression output range를 잘 튜닝하는 방법, [논문 리뷰] PP-YOLO v1 (+v2) 참고)
- Anchor free detector에서는 이러한 트릭들이 필요없고 연산량도 줄어든다 (corner net, center net, FCOS 같은 detector들 참고)
- YOLOX에서는 다음과 같이 anchor을 제거한다
- 각 feature에서 1개의 물체의 정보만 예측한다 (anchor을 사용하는 YOLO는 보통 3개의 anchor을 사용하는데, 각 anchor마다 물체의 정보를 예측해야 하기 때문에, 3개의 물체의 정보를 예측한다).
- 예측 값: grid 의 왼쪽 위 코너에서 bbox 중심의 offset, width, height
- FCOS와 비슷하게 물체의 사이즈에 따라서 다른 feature level에 assign한다 (작은 물체는 feature map의 width, height가 큰 layer에 할당하고 큰 물체는 feature map의 width, height가 작은 layer에 할당한다)
- 물체의 중심 = positive (물체가 존제한다), 나머지는 negative (물체가 존재하지 않는다)로 설정하고 학습
Multi positives
- anchor free 섹션에서 설명한대로 학습하면 각 물체를 예측하는 feature 위치는 1개밖에 없기 때문에 학습이 비효율적일 수 있다 (negative가 많아서 positive/negative샘플들의 balance가 맞지 않을 수 있다)
- 따라서 물체의 center 주변의 3x3 window 안에 있는 feature들이 모두 물체를 예측하도록 한다
SimOTA
- OTA 기반으로 positive에 label assignment하는 방법 (OTA는 밑에 접은글 참고)
- ground truth와 prediction 을 match해줬을 때 얼마나 잘 match되었는지 판단하는 척도로 다음을 사용한다: \( c_{ij} = L^{cls}_{ij} + \lambda L^{reg}_{ij}\).
- \( \lambda\)는 hyperparameter
- \( L^{cls}_{ij}, L^{reg}_{ij}\): ground truth \(g_i\) 와 prediction \( p_j\) 사이의 classification & regression loss
- 각 \( g_i\)의 중심에 대해서 \( c_{ij}\) 가 가장 작은 k개의 prediction을 positive sample로 잡는다
- k는 ground truth마다 다르고 OTA와 같이 dynamic k estimation strategy를 사용한다
- OTA처럼 Sinkhorn-Knopp algorithm을 사용할 필요가 없어서 OTA에 비해 학습 속도가 빠르다
OTA 간단 설명:
OTA (optimal transport assignment):
논문은 https://arxiv.org/abs/2103.14259 참고
Earth mover's distance / optimal transport distance는 [정리] Earth mover's distance,참고
Sinkhorn distance는 [논문 리뷰] Sinkhorn Distances: Lightspeed Computation of Optimal Transport 참고
다음과 같은 문제를 풀기 위한 방법이다. object detection 모델에서 나오는 많은 prediction 중 어떤 prediction을 ground truth에 할당하는 것이 가장 효율적일가? 이것은 optimal transport 분야에서 푸는 문제와 동일하다. optimal transport 방법론을 gt <-> prediction assignment에 적용한 게 OTA다.
조금 더 구체적으로 설명하면 ground truth \(g_i\)를 prediction \( p_j\) 에 assign할 때 발생하는 cost를 \( c_{ij}\)라고 하자. 여기서 assign하는 방식을 \( \pi_{ij}\)라고 하자. 여기서 단 1개의 ground truth를 1개의 prediction에 할당할 필요는 없고, g_i는 s_i=k (supply)개의 prediction들에 할당될 수 있고, 각 prediction에 d_j=1 (demand)개의 gt가 할당될 수 있다. 수식으로 적으면 다음과 같다:
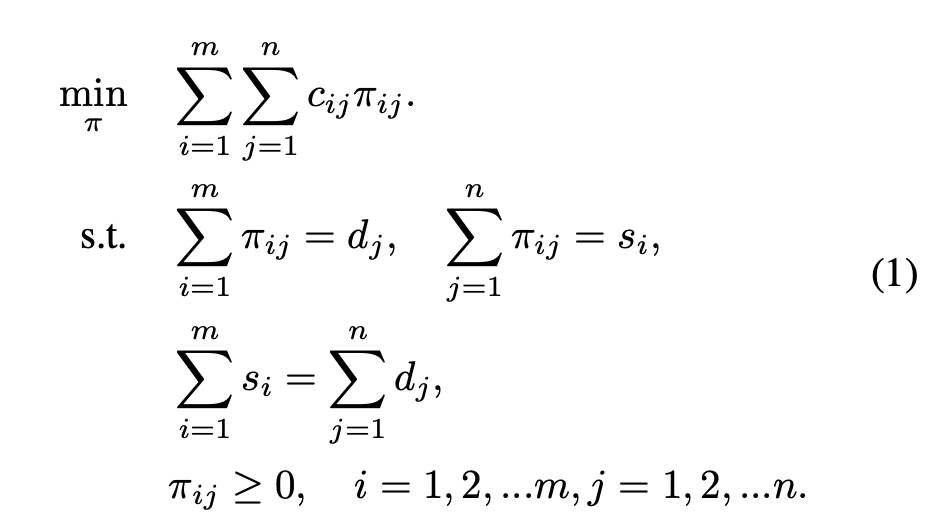
참고로 이것은 earth mover's distance / optimal transport distance라고 부른다. 이 문제를 그대로 푸는 것은 연산량이 좀 많이 필요해서 일종의 approximation으로 나온 것이 Sinkhorn distance라는 개념인데 자세한 내용은 이전글 참고.
object detection같은 경우 ground truth로 background도 있어야 하는데, background를 prediction에 할당하는 cost는 background class를 예측할 때 발생하는 classification loss를 사용한다.
그럼 k개의 supply를 1개의 demand로 할당할 때 k는 어떻게 설정하는가? OTA에서는 dynamic k estimation이라는 방법을 제안한다: 각 gt마다 IoU가 가장 높은 q개의 prediction을 선정한 후, IoU 값들을 모두 더해서 gt의 k 값으로 사용한다:

End-to-end YOLO
2개의 convolution layer을 추가하고 one-to-one label assignment, stop gradient를 사용해서 end-to-end 학습을 할 수 있는데 performance와 inference speed가 안 좋아지기 때문에 그렇게 중요하게 생각 안 해도 된다.
Backbone 실험들
- YOLOv5에서 사용한 CSPNet, SiLU activation, PAN head를 추가하고, scaling rule을 사용해서 YOLOX-S, YOLOX-M, YOLOX-L, YOLOX-X 모델들을 만들었다. YOLOv5와 성능 비교는 다음과 같다:

- YOLOX-Tiny: 모델을 더 작게 만든 버전, YOLOX-Nano: depth wise convolution을 사용한 모델. 다른 tiny 모델들과 성능 비교는 다음과 같다:

모델 사이즈와 data augmentation
모델 사이즈가 작으면 augmentation도 약하게 하는 것이 좋다고 한다
'논문 리뷰 > object detection' 카테고리의 다른 글
| [논문 리뷰] YOLOv7 (0) | 2023.07.14 |
|---|---|
| [논문 리뷰] YOLOv6 (0) | 2023.07.09 |
| [논문 리뷰] EfficientDet (0) | 2023.05.28 |
| [논문 리뷰] PP-YOLO v1 (+v2) (3) | 2023.05.26 |
| YOLOv5 정리 (2) | 2023.05.19 |