728x90
728x90
개요
논문 링크: https://arxiv.org/abs/2104.14294
알아야 할 것들: ViT, multi-crop augmentation ()
참고하면 도움 될만한 이전 글들 / 논문:
- [논문 리뷰] SwAV
- [논문 리뷰] MoCo-v1 (Momentum Contrast for Unsupervised Visual Representation Learning)
- [논문 리뷰] BYOL
- 요약:
- 이번에 리뷰하는 논문은 self-supervised learning 기법 중 하나입니다. 대부분의 저자들이 SwAV 논문 저자들과 동일한데, DINO의 핵심 아이디어는 SwAV 논문에서 제시했던 multi-crop augmentation을 self-distillation에 적용한 것이라고 생각하면 됩니다.
- 조금 더 구체적으로 teacher model에는 weak augmentation을 준 이미지를 통과시키고 (multi-crop augmentation에서 큰 crop만 사용), student model에는 strong augmentation을 준 이미지를 (multi-crop augmentation에서 큰 crop과 작은 crop 모두 사용) 통과시킨 후, teacher model과 student model 사이에 distillation loss를 주는 방식으로 학습합니다.
- 여기서 teacher model의 parameter은 student model parameter의 EMA (exponential moving average)로 업데이트해 줍니다.

- Figure 2에서 볼 수 있듯이, ViT를 DINO로 학습했을 때 [CLS] token의 self-attention map을 보면 segmentation 정보를 갖고 있다는 것도 특징적입니다. ViT를 supervised training 했을 때나 CNN architecture를 DINO로 학습했을 때는 이렇게 뚜렷한 segmentation map이 나오지 않는다고 합니다.
- 동시에 DINO로 학습한 feature은 classification에도 유용합니다.
- (DINO는 self-distillation with no label에서 따왔다고 합니다)

방법
알고리즘
Notation 정리
- x: 이미지
- \( g_{\theta_{s/t}} \): student / teacher network
- \( \theta_{s/t}\): student / teacher network parameters
- Student network feature (K 차원)으로부터 얻는 확률 값 (feature index, i=1,...,K):
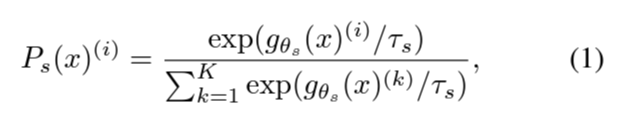
- \( \tau_{s}\): 확률을 구할 때 사용되는 temperature
- Teacher network에 대해서 \( P_t(x)\)는 \( \tau_{s} \rightarrow \tau_{t}\)로 교체해서 비슷하게 얻을 수 있습니다. 약간 다른 점은 centering이라는 해준다는 점인데, c를 center이라고 하면 다음과 같이 확률을 얻습니다 (c를 얻는 방법은 뒤에 설명)
\[ P_t(x)^{(i)} = \frac{\exp((g_{\theta_t}(x)^{(i)}- c)/\tau_t)}{\sum_{k=1}^{K} \exp(g_{\theta_t}(x)^{(k)}/\tau_t)}\] - Loss function: \( H(a,b) = -a \log b \) 사용
구체적인 알고리즘
- 이미지 x에 multi-crop augmentation을 해서 augmented view들을 얻습니다. 이들을 V라고 부릅니다.
- V를 구성하는 이미지 중 \( x_1^g, x_2^g\)는 multi-crop augmentation에서 global view고, 나머지는 local view입니다.
- global view는 이미지의 50% 이상 면적을 차지하도록 crop 합니다. 이때 224 x 224 사이즈로 crop 합니다.
- local view는 이미지의 50% 이하 면적을 차지하도록 crop 합니다. 이때 96 x 96 사이즈로 crop합니다.
- 이렇게 얻은 V로 다음과 같이 loss function을 계산합니다

- 식 (3)을 보면 알 수 있듯이, teacher은 global view만 보고 student는 local과 global view 둘 다 봅니다
- AdamW를 사용해서 식 (3)를 최소화하면서 \( \theta_s\)를 구합니다.
- \( \theta_t\) 는 student network의 parameter을 EMA 해서 구합니다 (student network의 parameter을 복붙 해서 teacher network를 업데이트해 주면 converge 하지 않는다고 합니다): \( \theta_t \leftarrow \lambda \theta_t + (1-\lambda) \theta_s\)
- 여기서 \( \lambda\)는 cosine schedule로 0.996에서 1로 올려준다고 합니다
- 위에서 언급했듯이 teacher network에 대해서 확률 값을 구할 때 centering을 하는데, center 값 \( c\)는 teacher network의 output에 대해서 EMA를 해서 얻습니다 (B는 batch size):

- 또한 teacher의 temperature parameter을 student의 temperature parameter보다 작게 잡는데, 논문에서 sharpening이라고 표현합니다 (확률 분포가 더 집중되기 때문에)
- centering과 sharpening이 collapse를 막는데 중요한 역할을 한다고 합니다.
- 알고리즘을 정리하면 다음과 같습니다

Network architecture
- \( g = h \circ f\)
- f = backbone (ViT 혹은 ResNet)
- h = projection head: 3-layer MLP (hidden dim = 2048) + l2 normalization & weight normalization. Output dimension = K
- BYOL / SimSiam 같은 방식과 다르게 predictor 사용하지 않았습니다
ViT에 대한 추가 detail
- ViT 같은 경우 이미지를 16x16 patch로 나눠서 사용합니다 (다른 patch size에 대한 실험은 있습니다)
- 학습 가능한 [CLS] token 추가. ViT를 classification에 대해서 학습할 때 [CLS]라고 불러서 비슷하게 [CLS]라고 부르지만 DINO 학습할 때 class label과 상관은 없습니다.
실험
학습 parameter
- Optimizer: AdamW
- batch size: 1024
- learning rate: 10 epoch동안 lr = 0.0005 x batchsize/256까지 올린 후 cosine schedule로 decay.
- AdamW의 weight decay도 cosine schedule로 0.04 -> 0.4로 스케즐링 했다고 합니다
- \( \tau_s = 0.1\)
- \( \tau_t \): 0.04에서 0.07까지 30 epoch동안 linear 하게 warm up 해줬다고 합니다
- Augmentation: color jittering, Gaussian blur, solarization (이 부분은 BYOL과 비슷) + multi crop
ImageNet 결과
밑에 있는 표에서 성능 평가 방법 (ImageNet에 대해서 pre-training 진행 후)
- Linear: ImageNet의 training data에 대해서 backbone f는 고정시키고, feature에 대해서 linear classifier 학습 (자세한 내용은 논문 appendix F 참고)
- k-NN: ImageNet의 training data의 feature을 저장해 두고, 테스트할 데이터에 대해서 저장해 둔 feature 중 가장 가까운 20개에 기반해서 어떤 class인지 추론 (자세한 내용은 논문 appendix F 참고)
- Fine tuning 같은 evaluation 방법은 fine tuning 할 때 사용하는 hyperparameter 의존도 때문에 사용하지 않았다고 합니다.

Distillation 관점을 저자들이 강조하는 이유:
- 밑에 학습 커브를 보면 알 수 있지만, teacher 의 성능이 student보다 좋기 때문에 mean teacher 같은 방법과 연관 지어볼 수 있기 때문입니다. ([논문 리뷰] Mean teachers are better role models 참고)

(추가 디테일은 논문 참고해 주세요)
728x90
728x90
'논문 리뷰 > self-supervised learning' 카테고리의 다른 글
| [논문 리뷰] SuperClass (Classification Done Right for Vision-Language Pre-Training) (0) | 2024.11.08 |
|---|---|
| [논문 리뷰] W-MSE (1) | 2023.06.03 |
| [논문 리뷰] MeanShift (2) | 2023.05.21 |
| [논문 리뷰] SNCLR (0) | 2023.05.21 |
| [논문 리뷰] self-supervised learning 이 항상 도움될까? (0) | 2023.03.30 |