728x90
728x90
개요
논문 링크: https://arxiv.org/abs/2303.17142
코드: https://github.com/ChongjianGE/SNCLR
관련 글:
SNCLR을 SimCLR & NNCLR과 비교하면 이해하기 좋다 (밑에 그림 참고). 우선 SNCLR은 SimCLR같이 contrastive learning에 기반한 self-supervised learning 논문이다. 밑에 (a) 같이 SimCLR은 같은 이미지의 다른 augmentation (결국 같은 이미지)를 positive pair로 사용한다. 반면 NNCLR에서는 (c)처럼 embedding space에서 nearest neighbor을 positive pair로 사용한다. SNCLR에서는 (d)처럼 positive pair을 nearest neighbor에만 한정시키지 않고, 주변에 있는 데이터들이 얼마나 (current instance와) 비슷한지 측정을 해서 이들을 soft positive pair로 사용한다. 이런 방면에서 NNCLR을 더 고도화한 논문이라고 볼 수도 있다 (SwAV는 batch에 있는 데이터를 를 여러 개의 cluster에 분할해 주는 방법이라 조금 다르다, [논문 리뷰] SwAV 참고)

방법
Contrastie learning framework
- MoCo, BYOL 같은 방법들과 모델의 틀은 비슷하다 (encoder, projector, predictor & momentum encoder, momentum projector을 사용), 밑에 그림 참고

- Batch (size = N)에서 sample x를 2가지 다른 방식으로 augmentation 해서 \(x_1,x_2\)라고 부른다.
- 각각 encoder & projector을 통과해서 \(y_1,y_2\)를 얻는다.
- Batch 안에 있는 N-1개의 다른 데이터는 모두 (momentum encoder & projector을 통과해서) negative pair이 되고, \( y_2^{i-}\)라고 표기한다 (여기서 i=1,...,N-1).
- 이때 loss는 다음과 같이 계산한다 (sim = cosine similarity, \( \tau\) = temperature)

- 여기서 predictor을 사용할 경우 \( y_1\) 대신 (z_1)을 사용하게 된다.
- encoder, projector, predictor은 gradient descent를 통해 학습하고, momentum encoder, momentum projector은 exponential moving average를 통해서 업데이트한다.
SNCLR (soft neighbors contrastive learning)
- 위에서 리뷰한 contrastive learning framework에서 positive pair을 같은 이미지의 다른 augmentation이 아니라 projected feature y1과 비슷한 y2들을 사용한다
- y2를 찾을 때 모든 데이터를 사용하는 것은 메모리와 계산량이 많이 필요하기 때문에 first-in-first-out (FIFO) queue를 다음과 같이 사용한다: 매 epoch마다 momentum encoder & momentum projector을 사용해서 y2를 계산해서 candidate set \( \mathcal{C}\)에 추가한다 (FIFO queue로 구현). \( \mathcal{C}\)에서 y1과 cosine similarity를 사용했을 때 가장 가까운 K개의 feature들이 NN(y2)가 된다:
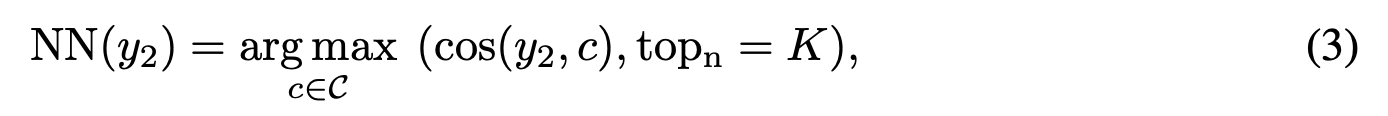
- 이렇게 선정된 neighbors를 기반으로 y1과 얼마나 비슷한지 나타내는 score \(w_i\)을 다음과 같이 계산한다

- 여기서 \( \gamma\)는 scaling factor, \( f_1,f_2\)는 identity가 된다 (여러 실험을 했을 때 identity일 때 가장 결과가 좋았다고 한다). 다시 말해서 \( w_i\)는 y1과 NN(y2) 사이의 softmax.
- 이렇게 구한 soft neighbor NN(y2) & similarity \(w_i\) 를 기반으로 SNCLR은 다음과 같은 loss function을 최소화한다:

- \( z_1\): \( y_1\)을 predictor에 통과시킨 값
- \(NN(y_2)_0 = y_2\)
- \(NN(y_2^{i-})_0 = y_2^{i-}\)
- \( w_0=1\)
- \( NN(y_2^{i-})\): negative pair \( y_2^{i-}\) & K개의 nearest neighbors
- Positive pair에 여러 개의 neighbor을 사용하는 장점: 특정 종의 강아지 사진이 있을 때 다른 종들의 강아지는 완전히 같은 positive pair이 아니지만 자전거보다는 비슷할 것이다. nearest neighbor만 사용하지 않기 때문에 이러한 similarity 정보를 사용할 수 있다
- Negative pair들도 batch 안에 있는 data만 사용하지 않기 때문에 다양성이 높아진다
- 예시:

Network architecture
- encoder: ResNet-50 (global context pooling 사용), ViT-S,ViT-B ([CLS] token 사용)
- projector, predictor: BYOL 과 비슷하게 2개의 fully connected layers 사용 (중간에 batch norm, ReLU 사용)
학습
- ImageNet-1k 데이터셋
- ResNet:
- LARS optimizer
- cosine annealing scheduler
- 800 epoch, 10 epoch=warm up
- lr = 0.3 x batch_size / 256
- momentum = 0.99 (momentum network 업데이트 파라미터)
- K = 30
- ViT: 살짝 다른 부분들
- AdamW
- 300 epoch, 40 = warm up
- lr = 1.5e-4 x batch_size / 256
결과
- 다양한 task에서 SOTA 성능을 보인다. 예를 들어 ImageNet에서 학습된 feature로 linear classification을 했을 때:
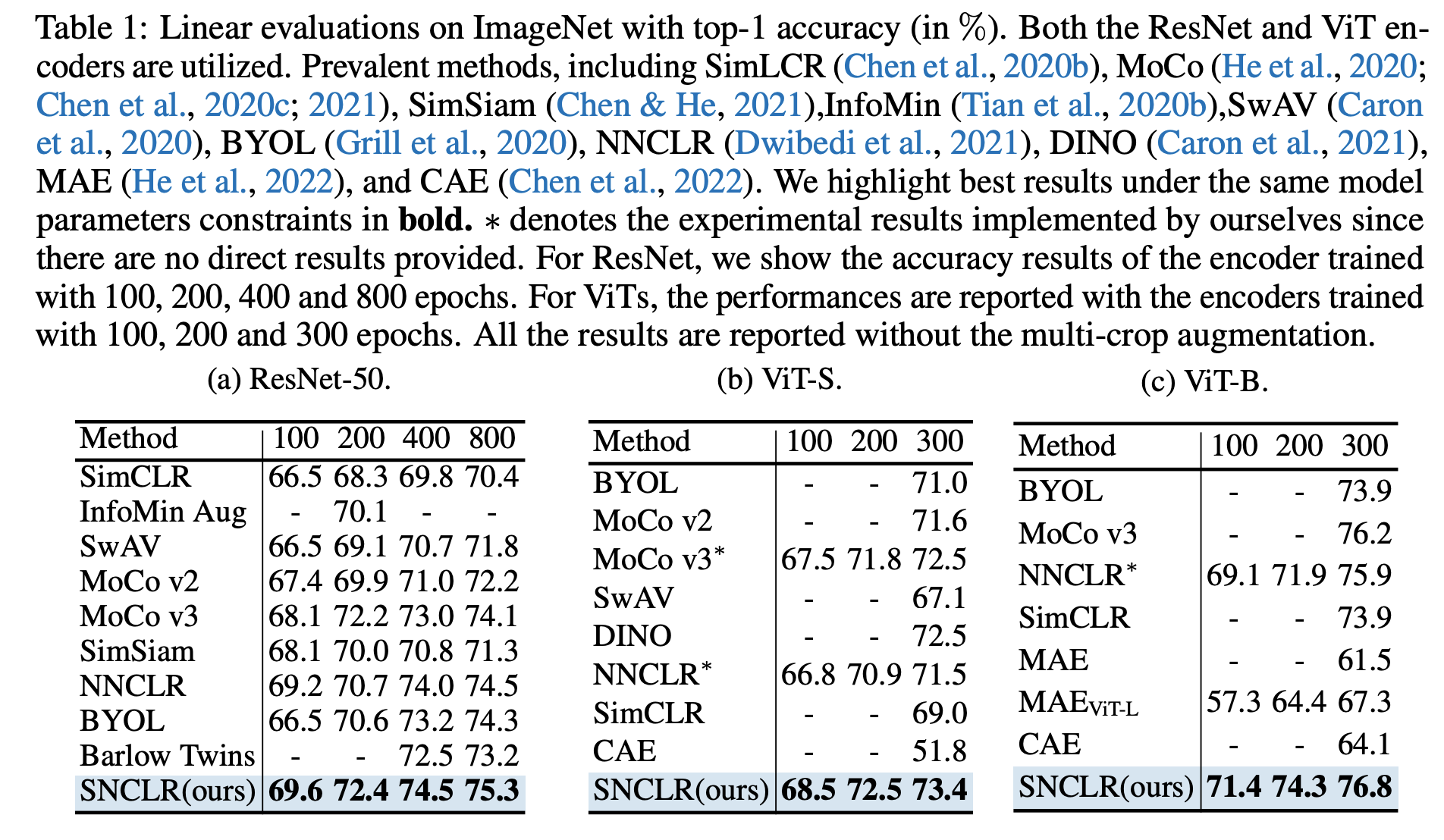
- semi-supervised training, object detection, segmentation에도 좋은 결과를 보였는데 자세한 내용은 논문 참고
728x90
728x90
'논문 리뷰 > self-supervised learning' 카테고리의 다른 글
| [논문 리뷰] W-MSE (1) | 2023.06.03 |
|---|---|
| [논문 리뷰] MeanShift (2) | 2023.05.21 |
| [논문 리뷰] self-supervised learning 이 항상 도움될까? (0) | 2023.03.30 |
| [논문 리뷰] NNCLR (0) | 2023.03.30 |
| [논문 리뷰] Barlow Twins (0) | 2023.03.17 |