728x90
728x90
개요
논문 링크: https://arxiv.org/abs/2104.14548 (With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations)
참고하면 좋은 이전 글:
아이디어는 매우 간단하다: SimCLR에서는 positive pair을 같은 이미지를 두 가지 방법으로 augmentation 한 pair이다. NNCLR의 아이디어는 한 이미지의 positive pair을 feature space에서 가장 가까운 다른 이미지로 잡는 것이다. 이런 간단한 아이디어를 추가하면 SimCLR의 성능이 많이 좋아진다 (다른 SOTA 성능들과 비슷). 다음 그림을 보면 이해가 빠를 것이다:
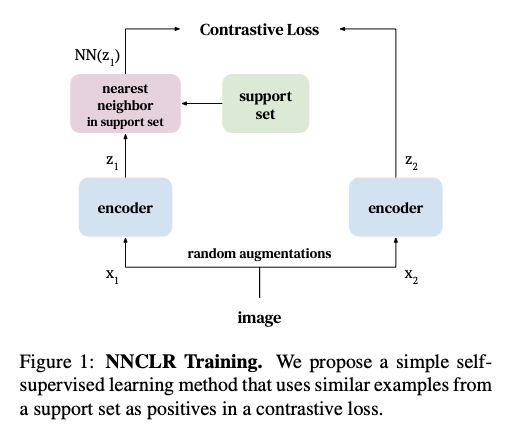
방법
NNCLR에 사용되는 기법들 간단 리뷰
InfoNCE:
- \( z_i\): i번째 이미지의 embedding
- \( z_i^+\): i번째 이미지의 positive pair의 embedding (다른 방식으로 augmentation한 이미지)
- \( z^- \in N_i\): i번째 이미지의 (많은) negative pair들
- InfoNCE loss는 다음과 같다:
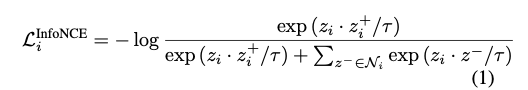
- 여기서 \( \tau\)는 temperature
- 아이디어는 embedding space에서 positive pair을 가깝게 모아주고 negative pair들은 멀리 보내는 것이다
SimCLR
- \( \phi\): ResNet50같은 neural network
- aug: augmentation transform
- positive pair \( z_i, z_i^+\)는 각각 이미지를 다른 방식으로 augmentation 해서 encoder을 통과시켜서 얻는다
- \( z_i = \phi(aug(x_i))\), \( z_i^+ = \phi(aug(x_i))\)
- negative pairs \( z_i, z^-\)들은 (큰) mini-batch에서 다른 i번째 이미지와 다른 이미지들로 얻는다.
- SimCLR loss는 다음과 같다 (InfoNCE loss에 positive pair, negative pair을 위에서 설명한 대로 적용한 loss). 참고로 밑에서 \( z_i\)들은 unit normalized 되어있다고 가정했다 (explicit 하게 적지는 않았다).
\[ \mathcal{L}^{SimCLR} = \frac{1}{n} \sum_{i=1}^{n} \mathcal{L}_i^{SimCLR}, \textrm{ where}\]

NNCLR (Nearest Neighbor CLR)
- augmentation만으로 positive pair을 만드는 것은 한계가 있다.
- classification에 특화되어있는 방법이기 때문에 classification에 대해 한정해서 설명하자면 간단한 augmentation으로 어떤 고양이를 같은 종의 다른 고양이를 만들 수는 없다. 하지만 embedding space에서 가까운 이미지는 이런 positive pair이 될 가능성이 있다.
- 구체적으로 z에 가장 가까운 embedding Q를 positive pair로 사용한다:
\[ NN(z,Q) = \textrm{arg}\min_{q\inQ} || z-q||_2 \quad (4)\]- Q는 support set이며, FIFO queue로 만든다. 학습하면서 계속 계산하는 feature들을 사용해서 업데이트한다.
- SimCLR와 loss의 차이점은 positive pair이 augmented image의 embedding이 아니라 embedding space에서 가장 가까운 embedding이라는 것이다:
\[ \mathcal{L}^{NNCLR} = \sum_{i=1}^{n} \mathcal{L}^{NNCLR}_i, \textrm{ where}\]
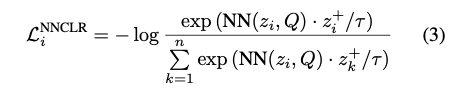
추가적인 디테일
- 다음과 같은 loss를 (3)에 추가해서 symmetric하게 만들어서 구현했다 (성능에 영향이 없어서 중요하지 않음)
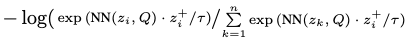
- \(z_i^+\) 대신 \( p_i^+\)를 사용했다. 여기서 \( p_i^+ = g(z_i^+)\), g는 MLP (BYOL의 prediction head와 비슷한 아이디어)
- 정리하면 다음과 같은 알고리즘이 나온다:

구현 디테일
- \( \phi\)는 ResNet-50 + MLP
- MLP: 3 layers [2048->2048->2048->256], 중간에 batch norm, ReLU 사용 (마지막 layer 제외)
- g: 2 layers [256->4096->256]
- ImageNet2012에 1000 epoch
- 10 epoch: warm up, cosine annealing scheduler
- LARS optimizer
- weight decay 10e-6
- weight decay를 bias에 적용 x
- BYOL과 같은 augmentation
- temperature = 0.1
- queue size = 98,304
- base lr = 0.3
- batch size = 4096
결과
 |
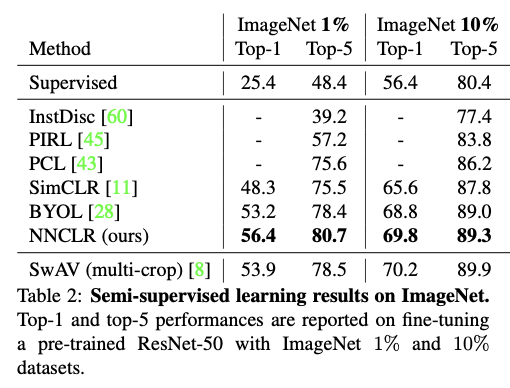 |
728x90
728x90
'논문 리뷰 > self-supervised learning' 카테고리의 다른 글
| [논문 리뷰] SNCLR (0) | 2023.05.21 |
|---|---|
| [논문 리뷰] self-supervised learning 이 항상 도움될까? (0) | 2023.03.30 |
| [논문 리뷰] Barlow Twins (0) | 2023.03.17 |
| [논문 리뷰] SimSiam (0) | 2023.03.13 |
| [논문 리뷰] SwAV (0) | 2023.03.11 |