개요
논문 링크: https://arxiv.org/abs/2002.05709 (A Simple Framework for Contrastive Learning of Visual Representations)
최근에 더 좋은 방법들도 있지만 중요한 논문입니다.
이런 류의 논문의 핵심은 레이블이 없는 이미지 데이터에 대해서 supervision 없이 학습시켜서 좋은 visual representation을 얻는 것입니다. 예를 들어서 ImageNet에 대해서 supervision 없이 neural net이 좋은 visual representation을 배우도록 학습시켰다고 합시다. 이런 visual representation (feature) 을 사용해서 linear classifier을 학습시키면 꽤나 좋은 성능이 나오는 것이 이 논문의 방법을 쓰면 가능합니다. 또한 이렇게 pre-training된 모델을 가지고 일부 데이터에 학습시키면 성능이 좋게 나올 수 있습니다.
방법
알고리즘

알고리즘을 이해하기 어렵지 않습니다:
1. N개의 이미지를 우선 샘플링하고 (x) 각 이미지마다 augmentation을 2번 해서 2N개의 augmented image \( \tilde{x}_i, \tilde{x}_j \)를 얻는다
- random crop (+random flip), random color distortion, random gaussian blur
2. 이 이미지를 neural net f를 통과시켜서 visual representation h를 얻는다.
- neural net으로는 ResNet 을 쓰는데 마지막 feature에 average pooling을 해서 얻는 값이 \( h_i \in \mathbb{R}^d \)
3. 이런 representation을 MLP g에 넣어서 z를 얻는다.
- \( z_i = g(h_i) = W^{(2)} \sigma (W^{(1)}h_i)\), W는 linear layer, \( \sigma\)는 ReLU
4. 이렇게 얻은 z에 contrastive loss를 사용: 아이디어는 샘플링한 이미지 중 같은 이미지를 augment한 pair의 z값은 ( \(z_i, z_j \) )비슷하고, 다른 이미지들에서 얻은 z 값은 다르다는 것을 학습하는 것. 구체적으로 loss function은
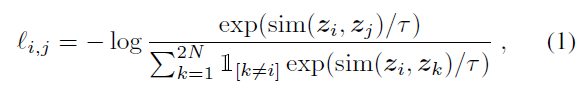
- \( \textrm{sim}(u,v) = u^T v / ||u|| ||v||\)
- \( \mathbb{1}_{[k\neq i]}\): k랑 i가 다르면 1, 같으면 0
- \( \tau \)는 온도
- 분모의 -log값은 \( z_i, z_j\)가 같은 방향인 벡터일 때 작고, 분자의 -log값은 \( z_i,z_k\)가 반대 방향일 때 작음
5. 최종 loss: \( \frac{1}{2N} \sum_{k=1}^N [\ell_{2k-1,2k} + \ell_{2k,2k-1}]\)
- 2k, 2k-1이 augmentation pair
마지막에 얻는 것은 neural net f는 keep; g는 버린다.
학습 세팅
기본 학습 세팅 (위에서 고정시키지 않은 부분들):
- Neural net은 ResNet 50
- Batch size = 4096. augmentation하면 총 8192 이미지라서 상당히 큰데 이 논문의 단점 중 하나입니다.
- 100 epoch 학습
결과
Image Net에 학습시켜서 나온 feature (ResNet을 통과시켜서 나온 h)를 사용해서 linear classifier을 레이블을 사용해서 학습시키면 Top 1이 69.3, Top 5이 89.0 accuracy가 나온다.

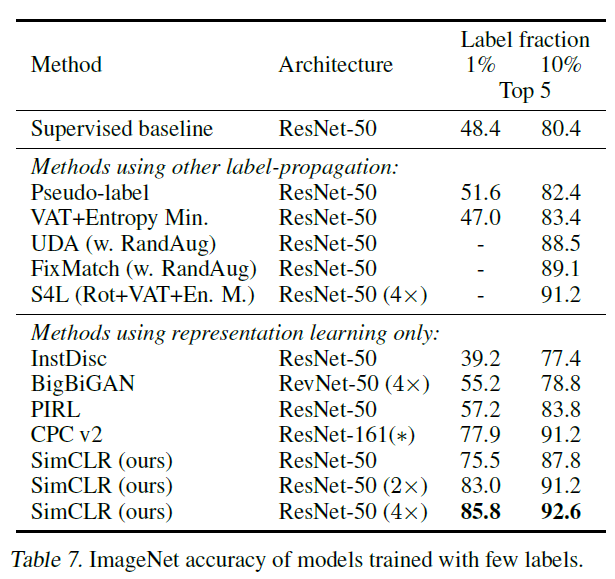
ImageNet에 pretraining시키고 각 class마다 일부의 레이블을 사용해서 neural net을 fine tuning해서 얻은 결과:
상대적으로 적은 레이블을 사용해도 괜찮은 결과를 얻을 수 있습니다. Supervised baseline은 Zhai et al "Self-Supervised Semi-Supervised Learning" (2019) 논문의 결과인데, 학습 hyperparameter 튜닝을 많이 해서 결과가 꽤 좋습니다. 이 baseline에 비해서 SimCLR을 사용해서 pre-training을 하면 훨씬 좋은 결과를 얻을 수 있습니다. 레이블링이 비싼 task인 경우 이런 학습 방식이 유용하겠죠.
'논문 리뷰 > self-supervised learning' 카테고리의 다른 글
| [논문 리뷰] BYOL (0) | 2023.03.01 |
|---|---|
| [논문 리뷰] DeepCluster (Deep Clustering for Unsupervised Learning of Visual Features) (1) | 2023.02.26 |
| [논문 리뷰] MoCo-v2 (0) | 2023.02.24 |
| [논문 리뷰] MoCo-v1 (Momentum Contrast for Unsupervised Visual Representation Learning) (0) | 2023.02.24 |
| [논문 리뷰] SimCLR-v2 (Big Self-Supervised Models are Strong Semi-Supervised Learners) (0) | 2023.02.19 |