개요
논문 링크: https://arxiv.org/abs/2006.10029
Semi-supervised learning: 보통 unlabeled data에 unsupervised/self-supervised 다음 labeled data에 supervised fine-tuning을 한다. 이 방법에서는 unlabeled data는 supervised training에 사용되지 않지만 이것은 낭비이다: supervised training에서 unlabeled data를 사용하는 방식들에 대해서도 연구가 많이 되어있다.
이 논문에서 다음과 같은 학습 방식을 제안한다 (SimCLR-v2):
- deep & wide network + (SimCLR에 비해) 새로운 projection head를 사용해서 pretraining
- labeled data로 fine-tuning
- unlabeled data로 distillation
pre-training할 때는 capacity가 크면 좋은 visual representation을 찾을 때 이득을 보지만, task-specific 할 때는 굳이 큰 capacity가 필요 없어서 더 작은 모델에 distillation해도 성능 저하가 거의 없다고 한다.
방법
Pre-training 방법:
기본적으로 SimCLR-v1과 같다. 전 포스트 참고 (https://curiouscat.tistory.com/9).
v2에서는 3가지 방식을 사용해서 더 좋은 성능을 낸다:
- 더 큰 network: ResNet-152 기반에 width를 3배 키우고, channel-wise attention mechanism (selective kernel)을 추가한 모델이 단순 ResNet-50에 비해서 훨씬 성능이 좋다
- 더 큰 projection head (g): SimCLR-v1에서는 g에 총 layer이 2개밖에 없었지만 (a) layer 수를 증가시키고 (b) g를 통째로 버리지 말고 몇 개의 layer을 남겨둔 채로 fine-tuning을 하면 더 좋은 결과를 얻을 수 있다
- MoCo와 비슷하게 memory mechanism을 사용하면 살짝 성능이 좋아진다. 구체적으로는 학습되고 있는 neural network의 parameter들을 exponential moving average를 취해서, negative sample들을 encoding해서 queue를 만들어서 사용한다. (SimCLR에서 이미 큰 batch size를 써서 큰 이득을 못 보는 것이라고 추측된다).
MoCo 관련 글 참고: <2023.02.24 - [paper review] - [논문 리뷰] MoCo-v1 (Momentum Contrast for Unsupervised Visual Representation Learning)>, <2023.02.24 - [paper review] - [논문 리뷰] MoCo-v2: Improved Baselines with Momentum Contrastive Learning>
모델 사이즈에 대한 실험:
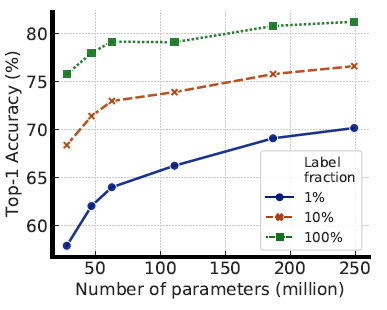
Fine-tuning 방법
위에서 언급했듯이 projection head g의 깊이를 증가시키고 g의 일부를 살리면 좋은 결과를 얻을 수 있다. 0번째부터 fine-tuning 한다는 뜻은 g를 통째로 제거하고 classifier head를 달아서 학습한다는 뜻 (기존의 SimCLR 방법).

Distillation 방법
Fine-tuned 모델을 teacher network로 사용하고 label이 없는 데이터에 teacher network를 사용해서 label을 만든다. 이 label을 student network에 distillation loss를 사용해서 학습시킨다:

Label이 있는 데이터가 많은 경우 labeled 와 unlabeled 데이터를 같이 사용하면 더 좋은 결과를 얻을 수 있다:

하지만 label이 적은 경우 labeled data를 사용하는 것이 거의 도움이 안 된다고 한다.
Distillation 결과인데, 여기서 가장 큰 모델은 ResNet-152에 width 를 2배로 키우고 selective kernel을 사용하였다. 자기 자신에게 distillation을 해도 결과가 좋아지기 때문에 (가장 큰 모델의 fine-tuned 결과와 self-distilled 결과 비교), 좋은 결과를 얻기 위해서 self-distillation을 하고 더 작은 모델에 distillation을 하는 방법을 추천한다.

'논문 리뷰 > self-supervised learning' 카테고리의 다른 글
| [논문 리뷰] BYOL (0) | 2023.03.01 |
|---|---|
| [논문 리뷰] DeepCluster (Deep Clustering for Unsupervised Learning of Visual Features) (1) | 2023.02.26 |
| [논문 리뷰] MoCo-v2 (0) | 2023.02.24 |
| [논문 리뷰] MoCo-v1 (Momentum Contrast for Unsupervised Visual Representation Learning) (0) | 2023.02.24 |
| [논문 리뷰] SimCLR (0) | 2023.02.01 |