개요
논문 링크: https://arxiv.org/abs/1911.05722
이 논문이 나올 당시에 contrastive learning을 통해서 좋은 visual representation을 학습하는 것이 성공적이었다 (SimCLR 등등). 이런 방법들은 보통 데이터를 neural network를 통과시켜서 encode 한다. 이렇게 encoded된 데이터가 query가 되고, query와 매칭되는 key (기본적으로 query와 동일한 데이터를 다양한 방식으로 가공해서 encoded된 값)는 당겨주고, 다른 데이터로부터 얻은 key들과는 밀쳐주는 방식으로 학습한다. 그리고 이러한 아이디어는 다양한 꼴의 contrastive loss를 최소화시켜주는 방식으로 구현을 한다.
이 방식이 잘 작동하려면 query와 비교할 대상들을(key) 잘 선정해야하는데, (1) key가 많아야하고 (2) 학습하면서 encoder network가 바뀌기 때문에 key도 encoder network와 consistent하게 바뀌어야한다. 기존에 방식들은 이 두가지를 동시에 만족시키지 않는 문제가 있는데, 이 방식을 'momentum'을 사용해서 해결하였다.
아이디어는 간단하고 다양한 contrastive learning에 일반적으로 적용할 수 있어서 좋은 논문이다.
방법
Notation
- \( x^q\), \( x^k\): query/key에 해당하는 데이터 (이미지)
- \(q=f_q(x^q)\), \(k=f_k(x^k)\) 는 각각 query, key
- \( f_q, f_k\) 는 각각 query와 key를 만들 때 사용되는 neural network. 서로 같을 필요는 없다
Momentum contrast
- queue는 first in first out 구조. key들을 저장한다.
- 한 batch를 프로세싱할 때 queue에 가장 예전에 들어왔던 batch로 만든 key들은 제거하고 새로운 데이터 batch로 만든 key들를 넣어준다
- batch size와 queue size를 이렇게 독립적으로 관리한다
- 이렇게 queue를 관리하면 key를 많이 만들 수 있지만, \( f_k\)에 back propagation을 하기는 어렵다. 간단한 해결 방법은 key 관련된 back propagagtion을 하지 않는 것인데, 이렇게 하면 좋은 결과를 얻지 못했다고 한다. 저자들이 추측하기로는 neural net이 gradient descent에 의해서 빠르게 바뀌어서 각 step마다 데이터의 representation의 consistency가 회손되기 때문이라고 한다.
- 해결책: \( \theta_q, \theta_k \)를 각각 \( f_q, f_k\)의 parameter이라고 하자. 그러면 다음과 같이 exponential moving average를 취한다: \( \theta_k \leftarrow m\theta_k + (1-m) \theta_q \), 여기서 \( m\in [0,1)\)은 momentum coefficient. 이렇게 하면 \( f_k\)는 천천히 evolve하기 때문에 encoded 된 값들이 smooth하게 바뀌고 consistency가 유지된다. m은 0.999정도로 큰 값이 좋다고 한다.
Pretext task
- pretext task란 neural net이 좋은 visual representation을 학습할 수 있도록 배우게 하는 task이다.
- 이 논문에서는 새로운 pretext task를 제시하는 것이 목적이 아니기 때문에 다른 논문에서 이미 제시된 pretext task를 사용한다.
- 우선 query와 key는 각각 \( f_q, f_k\)로 encoding 한다.
- 같은 이미지를 다르게 augmentation을 했으면 positive pair을 이루고, 다른 이미지로부터 얻은 key들은 (queue에서 가져옴) 모두 negative pair에 해당된다.
- loss는 \( -\log(P)\), \( P = \frac{e^{q \cdot k^+/\tau}}{\sum e^{q \cdot k/\tau}}\). 여기서 summation은 queue에 있는 positive pair & negative pairs에 대해서. \( \tau\) 는 temperature parameter. 참고로 여기서 key를 만드는 network 쪽으로는 gradient flow가 없다.
- 더 자세한 내용은 다음 알고리즘 참고:

Shuffling Batch Norm
- Batch Normalization을 할 때 조심해야한다고 한다.
- Batch normalization을 하면 batch 안에 있는 sample들 끼리 정보를 공유하게 된다 (feature을 계산할 때 batch에 대해서 mean, std를 사용해서 normalization을 해주기 때문에). 이러한 현상 때문에 좋은 representation을 학습할 때 방해가 된다고 저자들은 추측한다.
- 이것을 해결하기 위해서 multi-gpu로 학습할 때 샘플들을 다음과 같이 shuffle해준다.
- query를 계산할 때는 shuffling을 안한다
- \( f_k\)로 key를 계산할 때 sample들을 shuffle해서 여러 GPU들로 분산한다. 각 GPU에서 key를 계산해서 원래 순서로 다시 shuffle해준다.
- 이렇게 하면 query와 positive pair을 이루는 key는 서로 다른 statistics를 가지는 batch로 계산하게 되기 때문에 cheating을 못할 것이다
다른 방식들과 비교
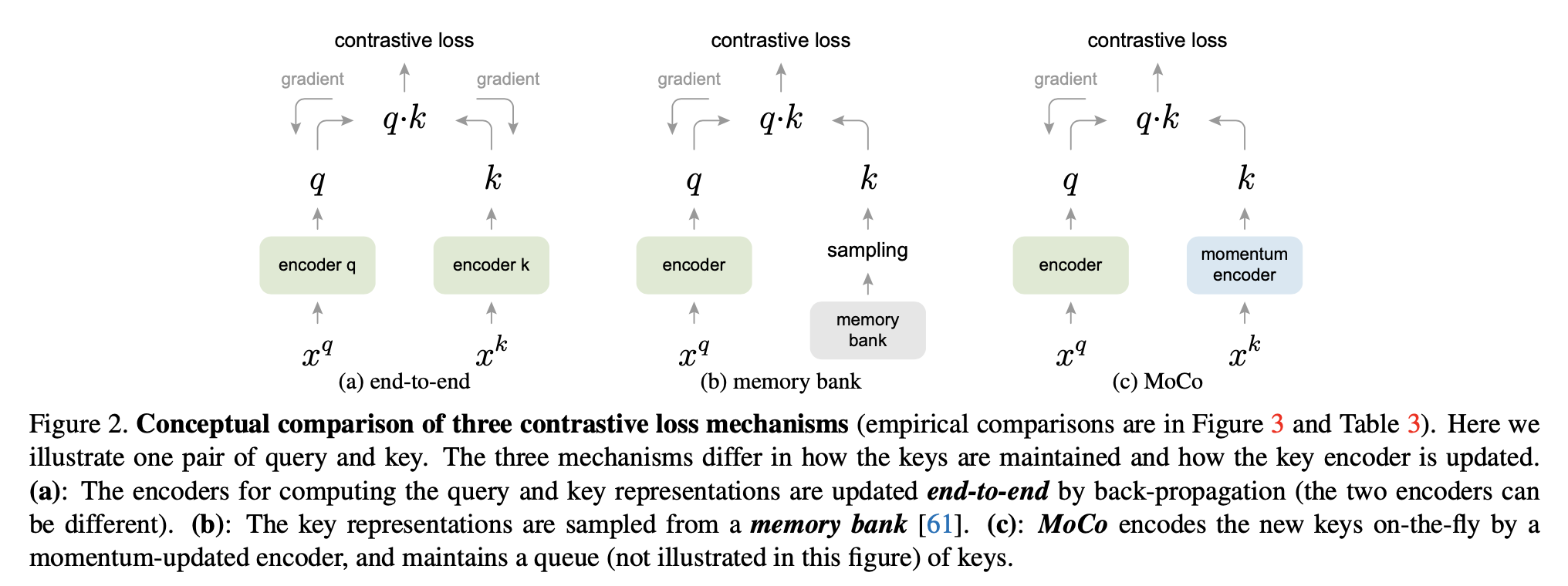
위에 있는 그림이 잘 설명해준다.
- end to end: 보통 큰 batch size를 필요로 한다. 이 batch에 있는 어떤 한 이미지를 query로 설정했을 때 다른 모든 이미지들이 negative pair을 형성한다 (같은 이미지는 positive pair, 다른 이미지들은 negative pair). 이렇게 한 query 이미지에 대해서 contrastive loss를 계산할 수 있고, batch에 있는 모든 이미지들을 query로 설정할 수 있기 때문에, 각 이미지에 대해서 contrastive loss를 더한 합을 최소화하는 것이 pretext task가 된다. 참고로 이 경우 gradient는 query를 만들 때 사용한 network와 key를 만들 때 사용한 network에 대해서 둘 다 계산한다.
- memory bank: contrastive loss를 계산하기 위해서 큰 batch를 사용하는 대신 memory bank를 사용하는 방식도 있다. 아이디어는 모든 이미지에 대응되는 representation을 저장해두고, 학습할 때 이 memory bank에서부터 sampling을 해서 contrastive loss를 계산하는 것이다 (이 때 memory bank에 있는 representation을 업데이트도 해준다). 이 방식에서는 이미지에 대응되는 representation을 계산할 때 사용되었던 neural network에 대해서는 gradient를 계산하지 않는다. 이 방식의 단점은 representation을 계산할 때 사용했던 neural network가 현제 neural network가 아닌 한참 전 neural network일 수도 있다는 것이다. 그래서 key들의 consistency가 회손된다.
- MoCo: exponential moving average된 neural network로 계산하기 때문에 consistency 문제가 해결된다. 추가로 batch size도 클 필요가 없다.
결과
다양한 down stream task에서 좋은 성능을 보인다. 다른 논문들과 비슷하게 학습된 feature로부터 linear classifier을 학습시키는 task를 포함해서 다양한 실험 결과들이 있다. 논문 참고.
'논문 리뷰 > self-supervised learning' 카테고리의 다른 글
| [논문 리뷰] BYOL (0) | 2023.03.01 |
|---|---|
| [논문 리뷰] DeepCluster (Deep Clustering for Unsupervised Learning of Visual Features) (1) | 2023.02.26 |
| [논문 리뷰] MoCo-v2 (0) | 2023.02.24 |
| [논문 리뷰] SimCLR-v2 (Big Self-Supervised Models are Strong Semi-Supervised Learners) (0) | 2023.02.19 |
| [논문 리뷰] SimCLR (0) | 2023.02.01 |