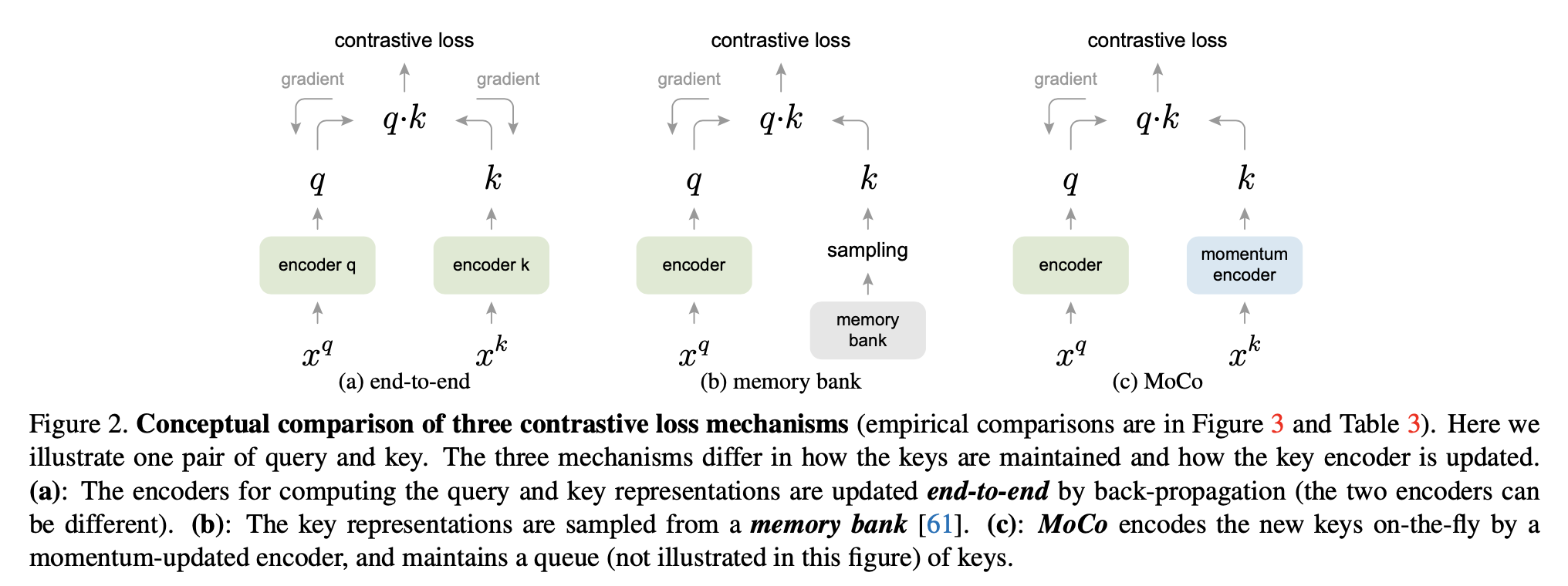
개요 제목: SELF-LABELLING VIA SIMULTANEOUS CLUSTERING AND REPRESENTATION LEARNING 논문 링크: https://arxiv.org/abs/1911.05371 관련 글: 2023.02.26 - [paper review] - [논문 리뷰] DeepCluster (Deep Clustering for Unsupervised Learning of Visual Features) 2023.02.18 - [paper review] - [논문 리뷰] Sinkhorn Distances: Lightspeed Computation of Optimal Transport ImageNet 같은 dataset에 classification task로 pre-trained netwo..