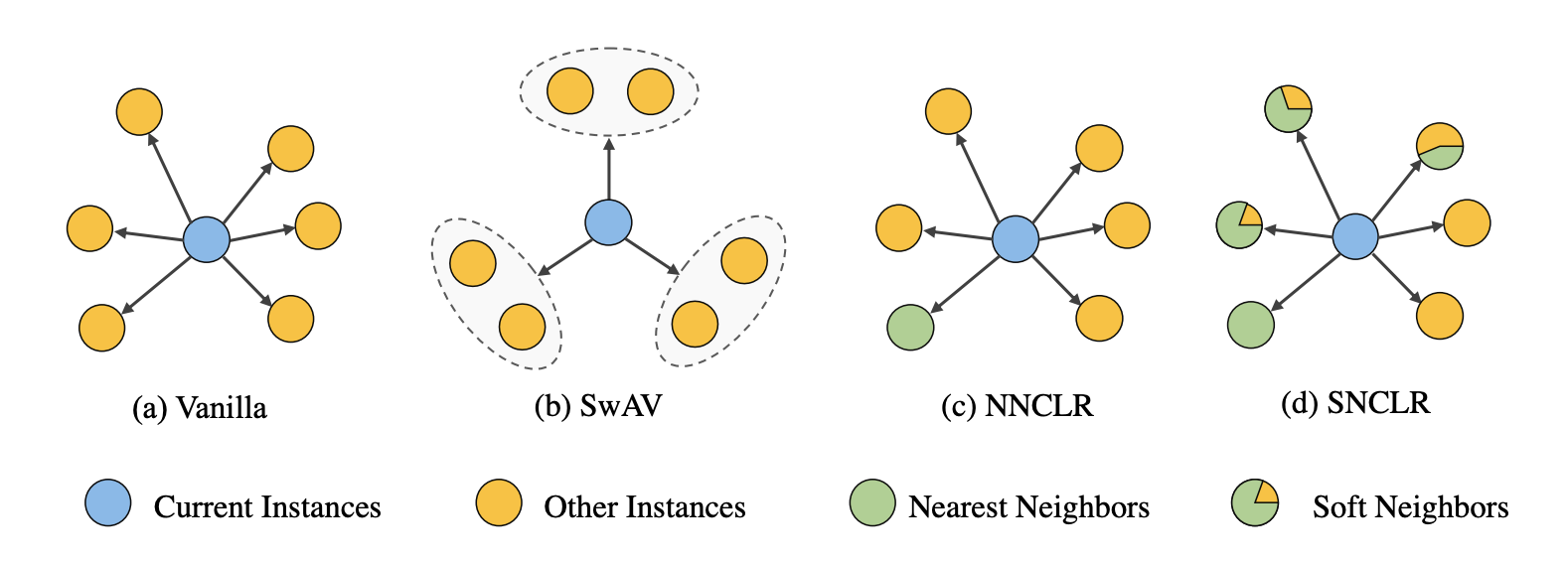
개요 논문 링크:https://arxiv.org/abs/2105.07269 관련 글: [논문 리뷰] BYOL, [논문 리뷰] SimSiam Self-distillation 기반의 self-supervised learning 기법이다. BYOL을 고도화한 방법이라고 봐도 될 것 같다. BYOL에서 한 이미지가 있으면 두 가지 방법으로 augmentation을 해서 각각 online encoder, target encoder을 통과한다. 그리고 online encoder을 통과한 embedding은 predictor을 통과해서 target encoder을 통과한 embedding을 예측하게 된다. MeanShift에서는 target encoder의 embedding을 그대로 예측하지 않고, embedding..